RedisGraph is a fast and easy-to-use graph database deployed as a Redis module.
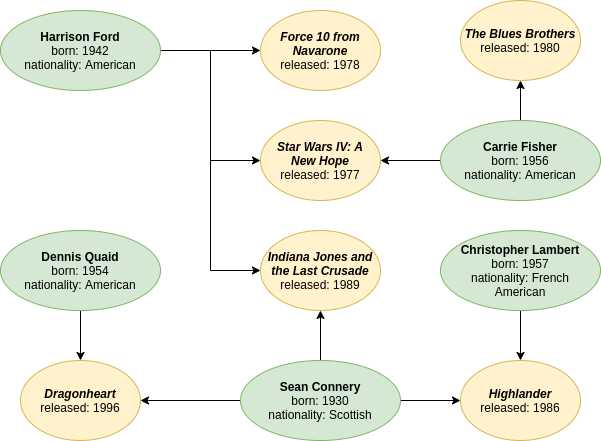
In Part 1, I explained how it works and the different ways to run it. I also presented an example involving films and actors, as seen in Figure 1 below for ease of reference, and showed how its data could be loaded into RedisGraph using a language called Cypher.
In this second part, I will run a number of Cypher queries on the data, demonstrating various ways to extract insights from graph data. Cypher shines because of its flexibility, and by the end of this article, you will also appreciate how intuitive it feels. In addition to that, I will also discuss further options for loading data into RedisGraph in scenarios with larger amounts of data.
Running Queries
Having already loaded the data for the example graph into RedisGraph, we can now run some queries. We can start with something really simple, like getting the name property of all nodes:
127.0.0.1:6379> GRAPH.QUERY FilmIndustry "MATCH (n) RETURN n.name"
1) 1) "n.name"
2) 1) 1) "Harrison Ford"
2) 1) "Carrie Fisher"
3) 1) "Sean Connery"
4) 1) "Dennis Quaid"
5) 1) "Christopher Lambert"
6) 1) "Force 10 from Navarone"
7) 1) "Star Wars IV: A New Hope"
8) 1) "Indiana Jones and the Last Crusade"
9) 1) "The Blues Brothers"
10) 1) "Dragonheart"
11) 1) "Highlander"
3) 1) "Query internal execution time: 0.959937 milliseconds"
Next, instead of returning everything, let’s return the list of films with their respective release dates:
127.0.0.1:6379> GRAPH.QUERY FilmIndustry "MATCH (f:Film) RETURN f.name, f.released"
1) 1) "f.name"
2) "f.released"
2) 1) 1) "Force 10 from Navarone"
2) (integer) 1978
2) 1) "Star Wars IV: A New Hope"
2) (integer) 1977
3) 1) "Indiana Jones and the Last Crusade"
2) (integer) 1989
4) 1) "The Blues Brothers"
2) (integer) 1980
5) 1) "Dragonheart"
2) (integer) 1996
6) 1) "Highlander"
2) (integer) 1986
3) 1) "Query internal execution time: 0.779738 milliseconds"
We can also slightly modify this query to return the year of release alongside the name of the film, using string concatenation not unlike what several SQL databases provide:
127.0.0.1:6379> GRAPH.QUERY FilmIndustry "MATCH (f:Film) RETURN f.name + ' (' + f.released + ')'"
1) 1) "f.name + ' (' + f.released + ')'"
2) 1) 1) "Force 10 from Navarone (1978)"
2) 1) "Star Wars IV: A New Hope (1977)"
3) 1) "Indiana Jones and the Last Crusade (1989)"
4) 1) "The Blues Brothers (1980)"
5) 1) "Dragonheart (1996)"
6) 1) "Highlander (1986)"
3) 1) "Query internal execution time: 0.875730 milliseconds"
127.0.0.1:6379>
Also like in SQL, we can add a WHERE clause to filter results. For instance, we can retrieve the list of actors born before the end of the Second World War:
127.0.0.1:6379> GRAPH.QUERY FilmIndustry "MATCH (a:Actor) WHERE a.born < 1946 RETURN a.name"
1) 1) "a.name"
2) 1) 1) "Harrison Ford"
2) 1) "Sean Connery"
3) 1) "Query internal execution time: 0.781336 milliseconds"
However, more interesting Cypher queries emerge around the relationships between nodes. For example, we can find out which films Sean Connery had a role in:
127.0.0.1:6379> GRAPH.QUERY FilmIndustry "MATCH (a:Actor)-[:actedIn]->(f:Film) WHERE a.name = 'Sean Connery' RETURN f.name"
1) 1) "f.name"
2) 1) 1) "Indiana Jones and the Last Crusade"
2) 1) "Dragonheart"
3) 1) "Highlander"
3) 1) "Query internal execution time: 1.194998 milliseconds"
Conversely, we can query who had a role in Star Wars IV: A New Hope:
127.0.0.1:6379> GRAPH.QUERY FilmIndustry "MATCH (a:Actor)-[:actedIn]->(f:Film) WHERE f.name = 'Star Wars IV: A New Hope' RETURN a.name"
1) 1) "a.name"
2) 1) 1) "Harrison Ford"
2) 1) "Carrie Fisher"
3) 1) "Query internal execution time: 1.178499 milliseconds
Taking this to the next level, we can actually find everybody who worked in a film alongside Sean Connery and in which films. This is a slightly more complicated query because the query path needs to connect two actors to each film, where one of the actors is Sean Connery and the other one isn’t (i.e., we need to exclude Sean Connery himself from appearing in the result set):
127.0.0.1:6379> GRAPH.QUERY FilmIndustry "MATCH (a1:Actor)-[:actedIn]->(f:Film)<-[:actedIn]-(a2:Actor) WHERE a1.name = 'Sean Connery' AND a2.name <> 'Sean Connery' RETURN a2.name, f.name"
1) 1) "a2.name"
2) "f.name"
2) 1) 1) "Harrison Ford"
2) "Indiana Jones and the Last Crusade"
2) 1) "Dennis Quaid"
2) "Dragonheart"
3) 1) "Christopher Lambert"
2) "Highlander"
3) 1) "Query internal execution time: 1.879676 milliseconds"
Finally, Cypher supports many of the aggregate functions that are familiar from SQL. For example, we can use the AVG() function to get the average age (roughly, and assuming we’re in 2020) of all actors in the graph with the following query:
127.0.0.1:6379> GRAPH.QUERY FilmIndustry "MATCH (a:Actor) RETURN AVG(2020 - a.born)"
1) 1) "AVG(2020 - a.born)"
2) 1) 1) "72.2"
3) 1) "Query internal execution time: 0.862926 milliseconds"
Update and Delete
The ubiquitous MATCH clause can also be used to locate existing nodes that we want to update or delete. For example, we can add a new property for children to Harrison Ford’s node:
127.0.0.1:6379> GRAPH.QUERY FilmIndustry "MATCH (a:Actor) WHERE a.name = 'Harrison Ford' SET a.children = 5"
1) 1) "Properties set: 1"
2) "Query internal execution time: 0.342000 milliseconds"
And we can also delete a node entirely. This also has the effect of removing any connected relationships. As an example, let’s remove Dennis Quaid:
127.0.0.1:6379> GRAPH.QUERY FilmIndustry "MATCH (a:Actor) WHERE a.name = 'Dennis Quaid' DELETE a"
1) 1) "Nodes deleted: 1"
2) "Relationships deleted: 1"
3) "Query internal execution time: 1.918727 milliseconds"
Loading Data into RedisGraph
Entering CREATE Cypher queries manually into redis-cli as we did in the previous section is a quick way to get some data into RedisGraph. However, for larger data sets, it can become very tedious.
Another option is to exploit redis-cli’s pipe mode. If we store our commands in a filmindustry.txt file, then we can execute them quickly using the following command from the terminal (i.e., outside of redis-cli):
cat filmindustry.txt | redis-cli --pipe
For much bigger scenarios, there exists a bulk insert API (GRAPH.BULK). This is in turn used by the redisgraph-bulk-loader utility. While this API is undocumented at the time of writing this post, it is still helpful to know that the option exists if the necessity arises.
Wrapping Up
Even from such a high-level overview, it’s evident that graph databases make it very easy and efficient to extract insights from intricate networks of related entities. Although a relatively new player in this field, RedisGraph shines because of its high performance, low storage requirements, and minimal dependencies.
Its adoption of the Cypher language is also a smart decision that makes RedisGraph very accessible both to developers with experience working with graph databases and to absolute beginners. Given that Redis is the most loved database according to Stack Overflow’s 2019 “Developer Survey Results” and there are therefore many people already using it, it becomes a no-brainer to add graph functionality to Redis rather than learn to administer and develop against a completely different tool.
Several client libraries for RedisGraph are available in most of the major programming languages as well, allowing RedisGraph to be used from software just as easily as from redis-cli.