Graph databases are a category of NoSQL storage engines that make it easy to represent and query highly connected data. While SQL databases can certainly be used to represent relationships, their performance is unable to keep up with that of graph databases at scale for large amounts of data with intricate relationships. Graph databases are also a lot more flexible in terms of schema and can answer questions about patterns in data relationships almost instantly.
Although many of us are used to using SQL databases for everything as a matter of habit, the applicability of graph databases is also very extensive. Example applications can range from the mundane (e.g., books and their authors) to different kinds of large-scale social networks (e.g., representing friends and relationships on Facebook or professional connections on LinkedIn). In recent years, the “Panama Papers” used graph databases to analyze and expose people implicated in financial crimes. Even the spread of a disease like the coronavirus can be modeled using a graph database.
While mainstream graph databases are more recent than SQL databases, they certainly aren’t something new. The graph database space is already a little crowded with several prominent players (e.g., Neo4j, TigerGraph, ArangoDB, etc.), cloud offerings (e.g., Amazon Neptune), and even SQL databases that have recently added some level of graph support (e.g., SQL Server).
RedisGraph is a fairly new graph database built as a module for Redis. It boasts great performance, supports the Cypher query language (used in other graph databases like Neo4j), and is very easy to get started with. In this post, I’ll give you a high-level overview of how RedisGraph works and what you can do with it.
How RedisGraph Works
RedisGraph uses a library called GraphBLAS, which allows it to both store the graph data in a very compact way and query it extremely quickly. As a result, benchmarks show that RedisGraph outperforms several of its most established competitors, which is quite surprising given that Redis is known to be single-threaded. But when you better understand the technology behind it, the reasons for this become clear.
While incoming requests use Redis’ single thread, they are then passed on to RedisGraph’s internal thread pool, which can execute different queries concurrently. At any given time, a query can only run on a single RedisGraph thread (although GraphBLAS may use additional threads as needed), unlike in competing graph databases where the same query is distributed across all cores of the machine. While this might seem counterintuitive, it’s better suited to handle high throughput and low-latency scenarios and therefore delivers better performance.
Setting Up RedisGraph
The RedisGraph homepage explains how to quickly try out RedisGraph. The easiest way by far to do this is to use Docker:
sudo docker run -p 6379:6379 -it --rm redislabs/redisgraph The above command will run the latest stable version, but if you want access to the latest features and fixes, you might want to use the edge tag instead:
sudo docker run -p 6379:6379 -it --rm redislabs/redisgraph:edge If you’re happy with RedisGraph and want to use it more seriously in a proper environment, you can also install it as a module in a self-hosted Redis instance. Or, for bigger scenarios, you can get it as part of Redis Enterprise Cloud.
Interacting with RedisGraph
We can use a language called Cypher to store and query data in RedisGraph. Originally created by competitor Neo4j and since developed in the openCypher project, Cypher uses both a form of ASCII art as well as SQL-like clauses to provide access to graph data, as we will see shortly.
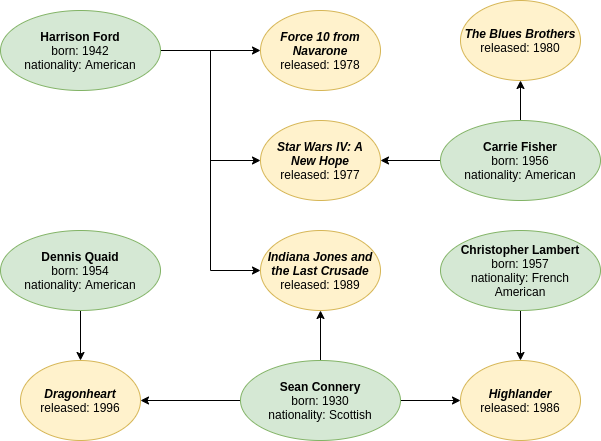
In order to show some basic queries, we’ll use the simple example shown in Figure 1. Directional arrows define actedIn relationships between actors (green nodes) and films (yellow nodes). For instance, Sean Connery acted in Highlander. This is only a subset of each film’s cast or each actor’s filmography in the interest of conciseness, but it is enough data to perform some interesting queries.
Loading Example Data
Through the same redis-cli client tool that we use for any other Redis commands, we can issue commands to RedisGraph. Let’s start by creating the actors:GRAPH.QUERY FilmIndustry "CREATE (:Actor { name: 'Harrison Ford', born: 1942, nationality: 'American' } )"
GRAPH.QUERY FilmIndustry "CREATE (:Actor { name: 'Carrie Fisher', born: 1956, nationality: 'American' }) "
GRAPH.QUERY FilmIndustry "CREATE (:Actor { name: 'Sean Connery', born: 1930, nationality: 'Scottish' } )"
GRAPH.QUERY FilmIndustry "CREATE (:Actor { name: 'Dennis Quaid', born: 1954, nationality: 'American' } )"
GRAPH.QUERY FilmIndustry "CREATE (:Actor { name: 'Christopher Lambert', born: 1957, nationality: 'French American' } )"
This might look a little strange because we’re actually sending Cypher queries inside of Redis commands. You need to read each command as: GRAPH.QUERY redis_key “cypher_query”. In each Cypher query, we are creating a node of type Actor, with the properties of name, date of birth, and nationality.
In a similar fashion, we can add Film nodes, each with the properties of name and release date:
GRAPH.QUERY FilmIndustry "CREATE (:Film { name: 'Force 10 from Navarone', released: 1978 } )"
GRAPH.QUERY FilmIndustry "CREATE (:Film { name: 'Star Wars IV: A New Hope', released: 1977 } )"
GRAPH.QUERY FilmIndustry "CREATE (:Film { name: 'Indiana Jones and the Last Crusade', released: 1989 } )"
GRAPH.QUERY FilmIndustry "CREATE (:Film { name: 'The Blues Brothers', released: 1980 } )"
GRAPH.QUERY FilmIndustry "CREATE (:Film { name: 'Dragonheart', released: 1996 } )"
GRAPH.QUERY FilmIndustry "CREATE (:Film { name: 'Highlander', released: 1986 } )"
Finally, we can create the relationships between the actors and the films:
GRAPH.QUERY FilmIndustry "MATCH (actor:Actor { name : 'Harrison Ford' }), (film:Film { name : 'Force 10 from Navarone' }) CREATE (actor)-[:actedIn]->(film)"
GRAPH.QUERY FilmIndustry "MATCH (actor:Actor { name : 'Harrison Ford' }), (film:Film { name : 'Star Wars IV: A New Hope' }) CREATE (actor)-[:actedIn]->(film)"
GRAPH.QUERY FilmIndustry "MATCH (actor:Actor { name : 'Harrison Ford' }), (film:Film { name : 'Indiana Jones and the Last Crusade' }) CREATE (actor)-[:actedIn]->(film)"
GRAPH.QUERY FilmIndustry "MATCH (actor:Actor { name : 'Carrie Fisher' }), (film:Film { name : 'Star Wars IV: A New Hope' }) CREATE (actor)-[:actedIn]->(film)"
GRAPH.QUERY FilmIndustry "MATCH (actor:Actor { name : 'Carrie Fisher' }), (film:Film { name : 'The Blues Brothers' }) CREATE (actor)-[:actedIn]->(film)"
GRAPH.QUERY FilmIndustry "MATCH (actor:Actor { name : 'Sean Connery' }), (film:Film { name : 'Indiana Jones and the Last Crusade' }) CREATE (actor)-[:actedIn]->(film)"
GRAPH.QUERY FilmIndustry "MATCH (actor:Actor { name : 'Sean Connery' }), (film:Film { name : 'Dragonheart' }) CREATE (actor)-[:actedIn]->(film)"
GRAPH.QUERY FilmIndustry "MATCH (actor:Actor { name : 'Sean Connery' }), (film:Film { name : 'Highlander' }) CREATE (actor)-[:actedIn]->(film)"
GRAPH.QUERY FilmIndustry "MATCH (actor:Actor { name : 'Dennis Quaid' }), (film:Film { name : 'Dragonheart' }) CREATE (actor)-[:actedIn]->(film)"
GRAPH.QUERY FilmIndustry "MATCH (actor:Actor { name : 'Christopher Lambert' }), (film:Film { name : 'Highlander' }) CREATE (actor)-[:actedIn]->(film)"
Although there seems to be a lot going on here, it’s actually quite simple. Instead of recreating Actor and Film nodes, we locate the ones we already have, MATCH each by name, and then establish the relationship between them. In every case, the relationship syntax looks like this: (actor)-[:actedIn]->(film). Cypher uses a syntax where nodes are denoted in round brackets, whereas edges are indicated by square brackets, and the symbols in between depict an arrow in the direction of the relationship.
What’s Next
So far, I’ve explained what RedisGraph is and how it’s powered by the GraphBLAS library. I’ve also discussed options for running RedisGraph. Finally, I’ve presented a small but practical example of a graph involving actors and films and shown how the data for this graph can be loaded into RedisGraph thanks to the Cypher language.
However, the capabilities of RedisGraph are best understood when seeing its querying capabilities. So stay tuned for Part 2, where we cover Cypher queries with RedisGraph, and further discuss options for loading data into RedisGraph.