
When Amazon introduced Lambda in 2014, it was an absolute game changer. While it wasn’t the first serverless compute service or even the first Function as a Service (FaaS) product, Lambda quickly and undoubtedly became the most well-known product in these areas. And for good reasons: It made running code possible without thinking about servers, and its pricing model was the cherry on top. It took roughly a year and a half from the introduction of Lambda for Microsoft and Google to start offering their own FaaS products, which, in the end, didn’t bring much–if anything–new to the table.
Fast forward to 2019, when Google introduced Cloud Run, the first serverless product since Lambda to catch my interest. Could this be the first real innovation in serverless computing since Lambda? After all, Lambda does have certain limitations that would be nice to see addressed–either by AWS or its competitors.
In this three-part series, I’ll be comparing Cloud Run to Lambda to find out where it comes out ahead (or falls behind), and which use cases may be better suited to each product. This comparison may start out on paper, but we’ll then put the price and performance of each product to the test with publicly reviewable benchmarks (to be as transparent as possible).
Personal opinions are marked as such. Let’s begin!
Cloud Run
Cloud Run runs containers and seamlessly handles scaling from zero to thousands of containers, all while charging only for the time used to run the code. Sound familiar? At a high-level, Cloud Run is to containers what Lambda is to functions. In fact, the pricing model is even the same: compute time is rounded up to the nearest 100 ms, with an additional fixed fee per request.
So is Cloud Run similar to AWS Fargate? Both run containers in a serverless fashion, but Fargate still requires a container orchestrator like Amazon ECS or EKS, while Cloud Run is a standalone solution. And although Fargate does have per-second billing, there’s a one-minute minimum, making it more suitable for longer-running tasks.
But before we get ahead of ourselves, you should know where Cloud Run came from to better understand the product. And that story starts with Knative.
Knative
Back in 2018, Google, in partnership with companies including Pivotal Software (now VMware) and Red Hat, released Knative, yet another open-source serverless platform for Kubernetes. There were already several other projects in this space, including OpenFaas, OpenWhisk, and Kubeless. Knative’s differentiator was its aim to provide the building blocks needed to make serverless applications a reality on Kubernetes and not necessarily be a full-blown solution by itself.
Epsagon released a good comparison between Knative and other serverless frameworks for those who wish to learn more. For developers, Knative brings a set of high-level APIs that make it easy to run applications on Kubernetes using industry best practices.
As of now, Knative has two main components:
- Knative Serving handles deploying, running, and scaling containers, plus the routing of HTTP requests to the containers.
- Knative Eventing provides a declarative way to manage channels and subscriptions of events, with pluggable sources from different software systems. Events are delivered via HTTP, for example, to a Knative Serving service.
But how does all of this relate to Cloud Run?
Knative and Cloud Run
While Knative itself requires Kubernetes, Cloud Run was born from the Knative Serving API, which it implements almost fully. But Cloud Run is a fully managed service on its own without Kubernetes. To learn more about the differences and the unsupported parts of the API, I recommend reading “Is Google Cloud Run really Knative?”
In practice, the same applications and manifests can be ported between Cloud Run and Knative on Kubernetes with minimal to no changes.
Lambda vs. Cloud Run: On Paper
To me, Cloud Run took some of the best parts of Lambda while also attempting to improve on others. Let’s start by seeing what they have in common.
Note: the term “call” is used from here on out to refer to either a Lambda invocation or a Cloud Run request, seeing as each service uses a different term for what is essentially the same thing.
Scale-to-Zero
Both solutions support scaling to zero, with billing in increments of 100 ms, which was always one of my favorite features of Lambda. It doesn’t matter if you have one service deployed or thousands; you only pay for the compute time resulting from a call, not for idle time.
Statelessness
Due to the highly ephemeral nature of the containers and functions in these runtimes, along with the horizontal scalability they provide, all code must be stateless. Any state should always be stored elsewhere, and both cloud providers offer excellent services where states can be stored and which can be accessed from code running on either service.
Concurrency Model
Here is where things start to differ. The concurrency level for any running Lambda function is always 1, meaning that each Lambda invocation can handle a single request at a time. During a spike of concurrent invocations, additional Lambda functions are needed, which may add to latency if they incur a cold start.
I see the Lambda concurrency model mostly as an issue for latency-critical applications, especially when traffic is unpredictable and cold starts are frequent.
Cloud Run, on the other hand, allows for a concurrency limit to be set per container, from 1 to 80. In theory, for I/O-bound code, a single container should be able to handle multiple requests without the need to incur additional cold starts. And because pricing is tied to the compute time of a container, concurrent requests on the same container can be handled for little to no extra cost.
It would be good to see Lambda unlock this concurrency limitation. Azure Functions, for example, does allow multiple concurrent execution on the same instance, as seen in this AWS Lambda vs. Azure Functions comparison.
CPU and Memory
The CPU and memory options for Cloud Run and Lambda are relatively different.
Lambda lets you pick the memory amount that’s available for a function, currently between 128 MB and 3,008 MB, in fixed increments of 64 MB. In Cloud Run, you can define any amount of memory between 128 MB and 2,048 MB (a lower limit than Lambda), and you can also pick either 1 or 2 vCPUs.
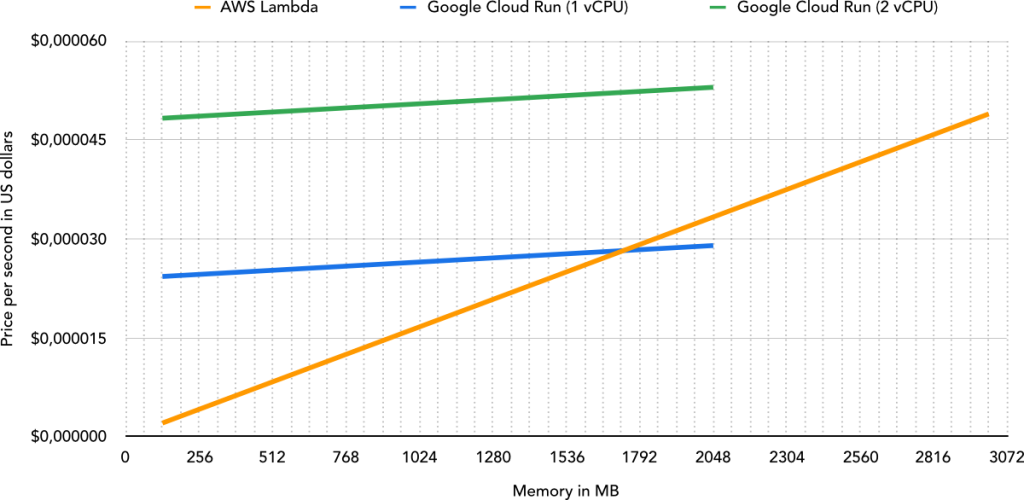
At first glance, it seems that Cloud Run is almost always more expensive. However, it’s vital to understand that CPU performance in Lambda is directly tied to the allocated memory. A Lambda function with 1,024 MB of memory has 8x the CPU performance of one with 128 MB, but at 8x the cost.
For CPU-bound code, it’s impossible to compare the price between Lambda and Cloud Run without benchmarking the two. Likewise, for I/O-bound code, it depends on whether a Cloud Run container is handling multiple concurrent requests, which dramatically affects the price (theoretically, it could result in an 80-fold decrease in price).
In my opinion, Lambda’s pricing is much easier to estimate due to its concurrency model. With Cloud Run, I feel like the best we can do is calculate the worst-case scenario (concurrency = 1), throw our hands in the air, and conclude, “Well, it might be cheaper than that!”
HTTP Native
Cloud Run supports HTTP/2 natively. Every call to a Cloud Run container is an HTTP request, and it is the developer’s responsibility to start an HTTP server and handle the request. Meanwhile, AWS’ runtimes and SDKs for Lambda do all the heavy lifting so that developers only need to implement the event handlers.
Cloud Run does require a bit of extra work here, since most languages require a library/framework to help with the HTTP side of things. But exposing a service using HTTP does have a benefit: A container can be mapped directly to a domain (using HTTPS by default, at no extra cost), without necessarily requiring an API Gateway or load balancer, as is the case with Lambda.
Unfortunately, HTTP streaming is not supported by Cloud Run, which means that both WebSockets and streaming with gRPC are a no-go (although unary gRPC is supported). Lambda, on the other hand, does support WebSockets via the Amazon API Gateway. Since Knative supports HTTP streaming, this is something that I would personally like to see Cloud Run offer in the future.
It is also worth noting here that Lambda has a maximum request and response size of 6 MB for each. For binary (non-text) HTTP responses from a Lambda function, the actual size is even smaller because the response must be returned Base64-encoded. Cloud Run has a much higher limit of 32 MB for each, which can be useful when dealing with larger payloads.
Openness
Both Lambda and Cloud Run are proprietary systems, but that doesn’t mean they’re equally so.
Lambda has supported runtimes for multiple languages such as JavaScript (Node.js), Java, Python, and Go and supports custom runtimes as well, whereas Cloud Run uses standard OCI images (commonly known as Docker images). Existing applications that are stateless and containerized should be deployable to Cloud Run as is.
The only proprietary part of Cloud Run is the infrastructure running the containers, as the runtime, API, and image format are all defined by Knative. Cloud Run can also alleviate the concerns of vendor lock-in, since it can be replaced by Knative running on any Kubernetes cluster.
Provisioned Concurrency
Since the beginning of Lambda, there have been various hacks to keep functions “warm,” i.e., to prevent dreaded cold starts. Recently, AWS released the provisioned concurrency feature, finally allowing a configurable amount of Lambda functions to run continuously and be ready to work. It’s an easy solution to the common cold-start problem, and it supports auto-scaling that can automatically modify the provisioned concurrency over time based on real usage.
Similarly, Knative supports a minimum number of container instances, which is shown in the Cloud Run console, but is currently disabled with a message stating that it’s not yet supported.
What’s Next?
Now that we’ve compared the two products on paper, it’s time to put them to the test. Part 2 will cover benchmarks and feature an analysis to better understand the performance and price/performance ratio of both products. Based on the results, conclusions can be drawn as to which service is better suited to different use cases. Stay tuned!
