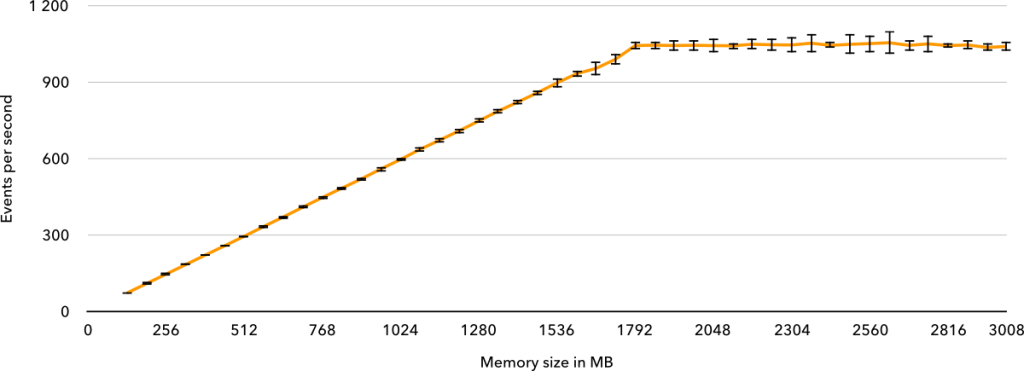
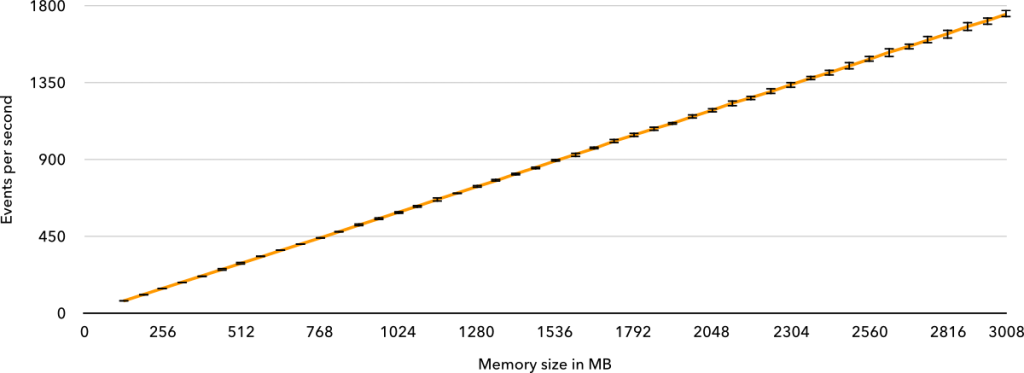
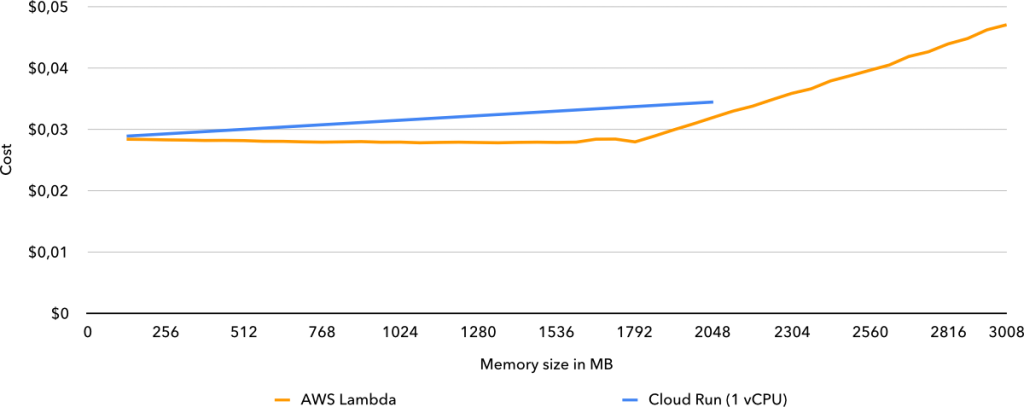
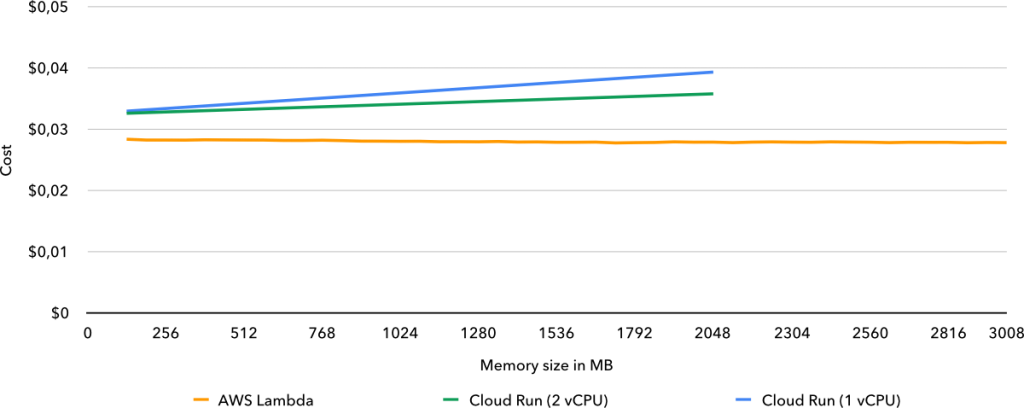
For purely CPU-bound tasks, Lambda came out on top as always being the cheapest option, with Cloud Run being anywhere between 1.8% and 28.2% more expensive, depending on the required memory. If Cloud Run supported more than 2 GB of memory at its current price and more than some 2.2 GB of memory were required, it would have been cheaper in the single-threaded benchmark.
Comparing to VMs
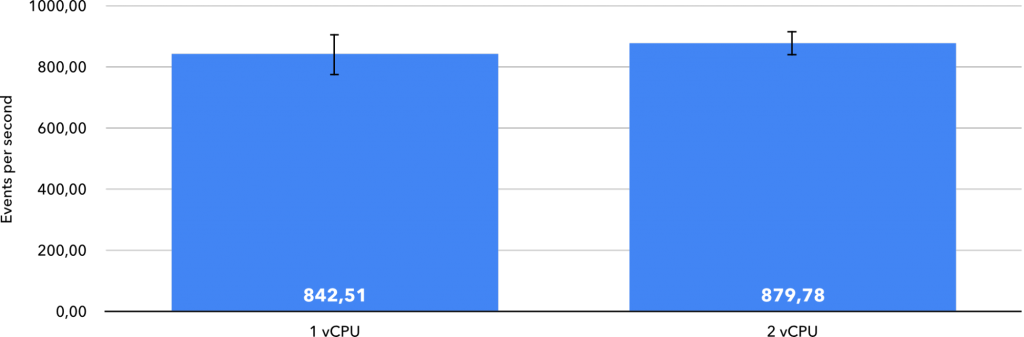
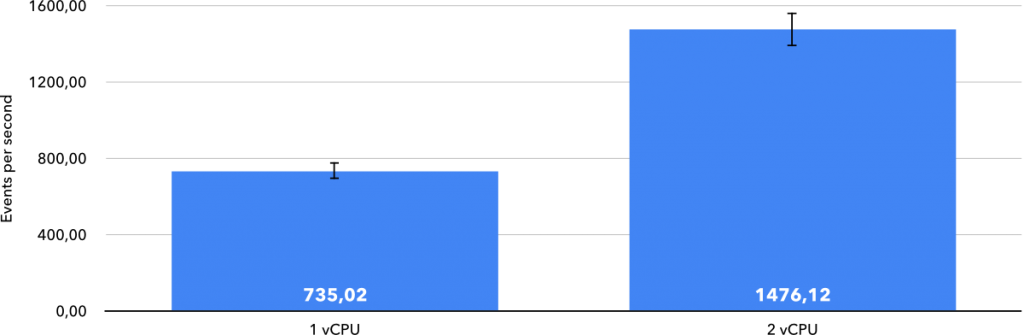
For a little bit of perspective, I thought it would be interesting to see how these numbers compare to VMs in both clouds. In the single-thread benchmark, a Google Compute Engine N1 instance scored 939.14 events per second, while an Amazon EC2 C5n instance scored 1,155.87 events per second, both using the Intel Skylake architecture. These serverless offerings do not stand very far from the VMs of their respective clouds in terms of single-thread CPU performance.
Unfortunately, I was not able to compare them with GCP’s latest N2/C2 instances, as these appear to be in such high demand that even my quota request for a single instance was rejected.
Cold Starts and Latencies
Cold starts have always been one of Lambda’s major limitations, but they are inevitable in platforms that not only scale to zero but also scale up automatically. And the cold start of a function or container is still much lower than that of a virtual machine, which is sometimes easy to forget. But let’s see how they compare between Lambda and Cloud Run.
For this benchmark, 200 calls were made to each service in batches of 10 parallel calls, with an environment variable change between each batch to trigger a cold start. The same was then performed but without the environment variable change to simulate warm calls. The response times were recorded, and their median used to calculate the difference. These tests were performed from VMs running in the same cloud and region as the Lambda function and Cloud Run service being examined to minimize any external factors.
For both services, the code was written in Go and did nothing but sleep for five seconds. The purpose of the sleep call was to ensure that no instance would be reused during the parallel calls, giving us more reliable results.
Lambda’s cold start time added 210 milliseconds to the response time, while Cloud Run’s cold start added a whopping 1,090 milliseconds. It appears that Lambda’s cold starts are currently 5.2x faster than Cloud Run’s.
VPC
This story, however, is a bit different when a VPC is involved. The Lambda cold start time when configured to access resources in a VPC was 404 milliseconds, whereas Cloud Run’s was 1,232 milliseconds. I find this result particularly interesting due to how they are implemented. Lambda’s VPC access is made possible through an Elastic Network Interface that the Lambda functions attach to, which is where the extra latency originates. Cloud Run, on the other hand, works by having a separate VPC connector running, which not only incurs additional (albeit small) charges but also requires provisioning throughput. Because the Cloud Run VPC connector is a separate component, I did not expect the cold start time to differ at all, whether a VPC was used or not. I hope Google can remove this difference, first because the cold start is already much higher than Lambda’s, but also because it increases the cost.
Latency
Using these same results, we can also analyze the latency of warm calls by comparing the difference between the time the code runs for (5,000 milliseconds) against the time between the request and response. The median Lambda latency was 51 milliseconds, while Cloud Run was only 32 milliseconds. Thus the observed Cloud Run latency was about 37% lower than Lambda from a VM in the same region.
Cloud Run Concurrency
Finally, we get to test the one feature where Cloud Run may take the lead. The hypothesis here is that for I/O-bound workloads, Cloud Run may be significantly cheaper than Lambda when there are concurrent requests, as a single container can handle up to 80 requests concurrently.
Because we’re testing for an I/O-bound scenario, I made one million requests to a Cloud Run service that sleeps for 200 milliseconds, with a concurrency level of 200. In the best-case scenario, this would result in being charged for just three container instances, which would be able to handle the entirety of the 200 concurrent requests. The reality, however, is that I was billed for about 19 container instances for the duration of the benchmark (slightly over 18 minutes).
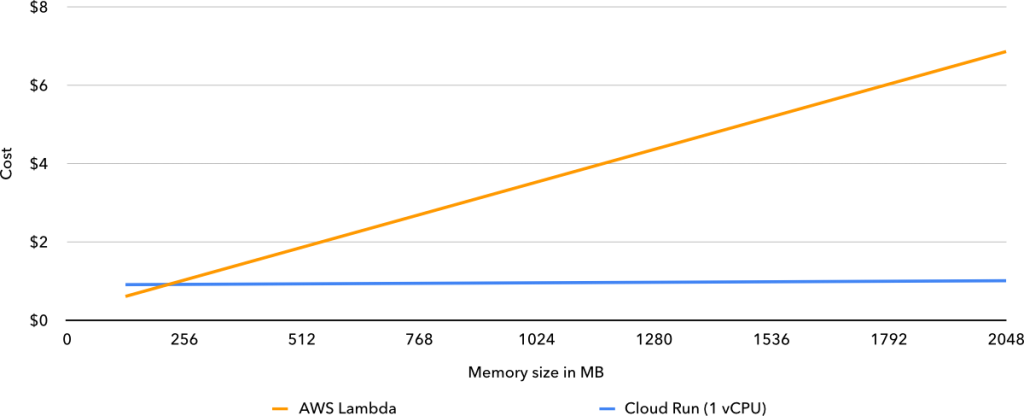
The exact way container instances get spawned (when and how) in Cloud Run is a black box and therefore a complete mystery, but I presume Google could further optimize it for cost. Even so, and as we can see from the chart below, Cloud Run can be over 6x cheaper than Lambda for I/O-bound concurrent workloads, depending on the allocated memory.