

When it comes to processing and storing big data, Apache Hadoop with Hadoop Distributed File System has always been a popular choice. Hadoop is well known for its ability to store a large amount of big datasets across clusters of commodity hardware and to handle large-scale data and file systems. Hadoop distributes these large datasets across nodes in a cluster and then breaks them down into more manageable workloads.
In this article, I’ll discuss some of the storage solutions you can use when moving the Hadoop functionality into the public cloud. Solutions that were previously not viable in an on-premises environment can offer unexpected benefits when used in a cloud implementation. In fact, you might even reconsider how you run your Hadoop cluster in general.
Hadoop in On-Premises Environments
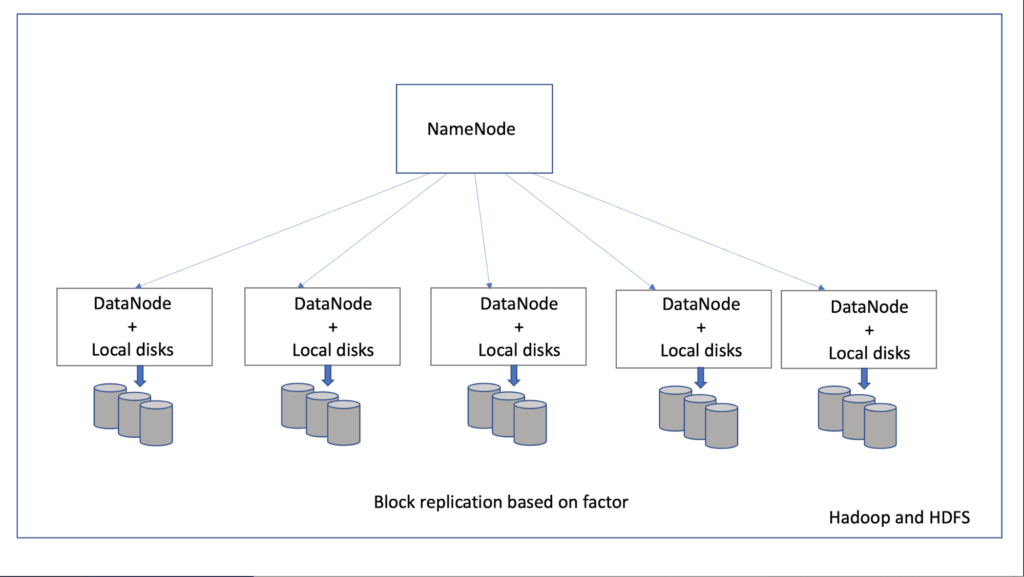
Let’s start with on-premises environments, where the administrator is responsible for managing the Hadoop cluster software and setting up the physical nodes with storage in the data center. A Hadoop cluster usually contains a NameNode and multiple DataNodes. The NameNode manages the file system namespace and controls client access to files. The DataNode manages its locally attached storage and services client requests.
Hadoop Distributed File System
Next up is Hadoop Distributed File System (HDFS), a distributed file system that allows access from multiple clients and is not restricted to a single access point. This happens when blocks of data are replicated to different machines, increasing both resilience and performance.
When data enters a DataNode, it lands in HDFS and is replicated to other DataNodes based on a replication factor. With a default replication factor of three, each block that enters a DataNode is replicated to two other DataNodes.
The advantage of this technique is that there is no single point of failure; losing a DataNode does not mean that you lose data. Also, different DataNodes service different clients, so the load is balanced across the cluster. It is fairly easy to add more DataNodes to the cluster in order to scale out. Just note that the amount of storage space you need can become extensive because of this replication.
Network File System
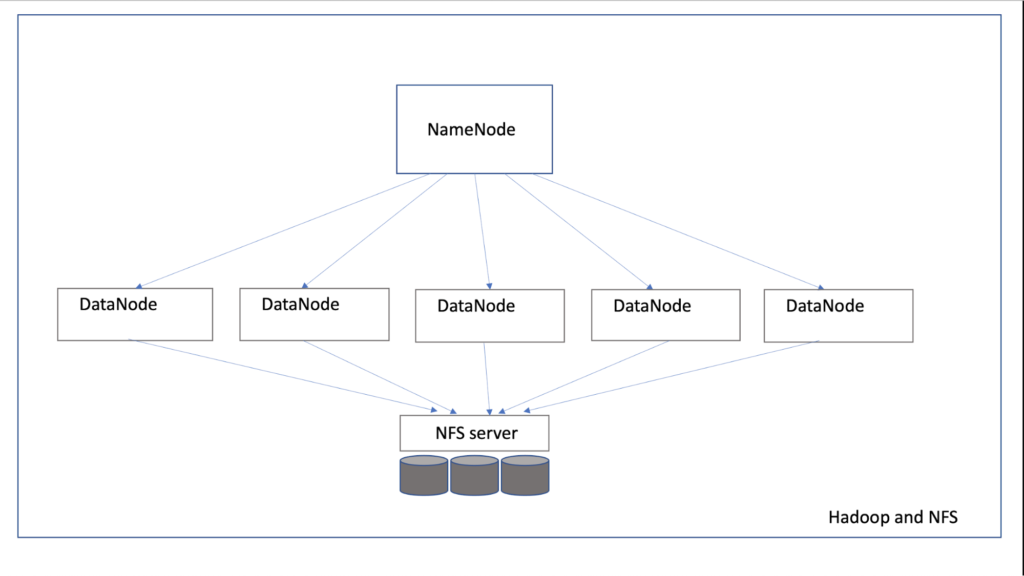
Another popular distributed file system is Network File System (NFS). A single NFS server manages its local file system structure and can share parts of it with any number of remote hosts. These so-called NFS clients can be enabled to mount and access file systems over the network, much like with local storage. NFS is a common solution in many environments because of its flexibility and ease of use.
With regards to performance and resilience, NFS is hosted by a single host that only gives you one access point, which could result in a bottleneck and reduced availability. Losing access to the host means losing access to the data. In addition, there is no replication of data, which reduces the data’s durability.
Running a Hadoop Cluster in the Public Cloud
To run a Hadoop cluster in AWS, you will need the same setup as in an on-premises environment, except that all nodes will be VMs. In this case, setup will be a lot quicker than when running physical machines. You can create HDFS by using either instance stores or Amazon Elastic Block Store volumes. Like with an on-premises cluster, the DataNodes will individually manage their own virtual storage environments.
The great thing about cloud computing is that monolithic applications can be converted into microservices. This means that since services are separated from each other (in a process commonly called decoupling), they can be independently managed.
However, this is not the case with DataNodes and HDFS, where each storage device is attached to a single DataNode and is only accessible when that node is up and running. In that respect, running a Hadoop cluster in AWS is the same as running it on premises; in order to get to the data, the DataNode that hosts the data must be in operation.
Another advantage of running cloud services is that you only pay for what you use. For example, decoupling the storage from the compute environment can save you money, since the VMs do not have to be up and running for others to access the storage.
Are You an Apache Hadoop Expert?
Amazon Elastic File System
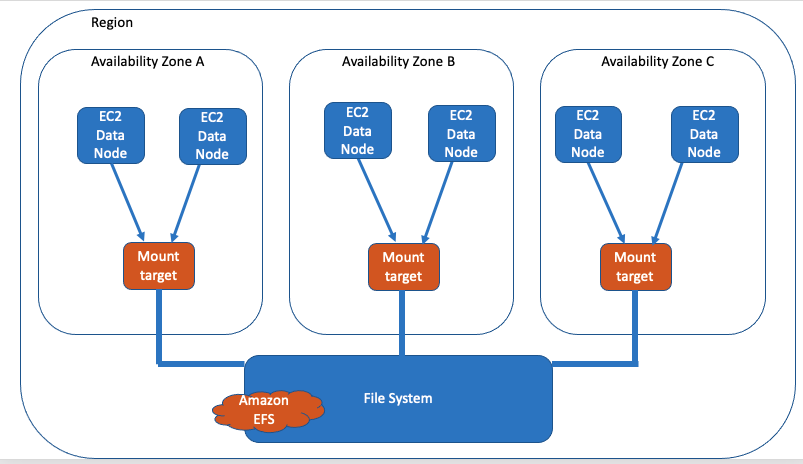
Amazon Elastic File System (EFS) is a fully managed service that offers mount targets to Amazon EC2 instances. This means that DataNodes can use an NFS mount target to connect to the EFS service and store the data in a managed file system. For example, you can use NFS as a service when you don’t want to worry about the server side of things, the amount of available space, or even the availability.
With EFS, each separate DataNode can connect to the same file system, which allows each file to be accessed by each DataNode. You will no longer need to replicate data, since EFS provides the availability. Also, the accessibility of EFS does not depend on the state of the DataNodes; data can still be accessed if you bring down the cluster. The NFS data space is virtually unlimited, so there is no need to scale out with regards to storage. Still, you may want to add more DataNodes to the cluster, which can then mount the same EFS environment.
Amazon EMR and Amazon S3
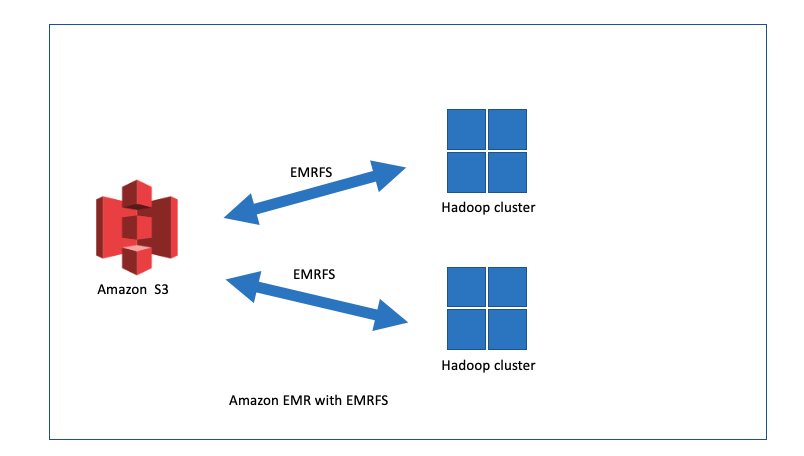
Instead of manually setting up a Hadoop cluster based on EC2 instances with instance stores, EBS volumes, or EFS, you can use Amazon EMR. This service will create and manage the EC2 instances that you need, scaling up and down when necessary.
Instead of the traditional HDFS solution, EMR uses the EMR File System (EMRFS). This is AWS’ implementation of HDFS, which utilizes S3 buckets to store data. With EMR, you can still run a cluster of nodes as you do in an on-premises solution or in a manually configured cluster in AWS with local EBS storage. But, as with EFS, the data is not directly attached to the different nodes in the cluster.
Amazon S3 is designed with 11 nines of durability in mind and removes the need to replicate data. As with EFS, the storage is decoupled from the compute instances. S3 functions really well in an environment with decoupled services. If data processing is not necessary, the compute instances can be shut down, which will result in lower costs. The data, however, is still accessible as needed.
Conclusion
Using HDFS in an on-premises Hadoop cluster is a tried-and-true solution with many advantages over other storage solutions, such as NFS. Still, when running a Hadoop cluster in AWS, you will need much more disk space for HDFS than when running the cluster in S3 or EFS. Because S3 and EFS safeguard the data’s durability and availability, there is no real need for replication. And they are not directly attached to the DataNodes in the cluster, contrary to the setup when using block storage.
S3 can store terabytes of data from nearly any source type, while providing superior performance, cost savings, scalability, and more. EMR, for its part, lets you archive log files in S3 so that you can troubleshoot issues on the fly—even after your cluster terminates. Because of this, S3’s durability makes it an excellent choice when it comes to processing big data.
Consider running an EMR environment with different workloads and schedules. EMR will manage the DataNodes based on the load and schedules that you provide, giving you impressive flexibility and cost savings for your big data storage and processing needs.
