The term “serverless” allows you to use a service without having to worry about where and how it is run. AWS offers multiple serverless options: Amazon S3, Amazon DynamoDB, Amazon SQS, Amazon SNS, Amazon SES, Amazon API Gateway, Amazon CloudFront, and more. It also offers serverless compute services, such as AWS Lambda, AWS Fargate, and AWS Step Functions, which allow you to run your own code without having to manage the underlying infrastructure. Although serverless has existed for a while, the serverless revolution really started with Function-as-a-Service (FaaS) offerings.
In this article, I’ll review how to modernize a traditional web application built using the usual three-tier system (web tier, app tier, and database tier), and will explore the associated benefits and drawbacks. The example in this article is hypothetical. Let’s assume that the web app uses a modern design, where most of the code runs on the client and occasionally makes API calls to the backend, when appropriate.
Making the Web Tier Serverless
Restructuring
The web tier can be made serverless using a combination of Amazon S3, an object-based storage system, and Amazon CloudFront, AWS’s content delivery network (CDN) offering. Both of these services are, by definition, serverless.
In a modern web-app design, the application is clearly separated into two categories:
- The files that are downloaded (and potentially executed) on the client. These are static files, such as HTML files, JavaScript code, images, fonts, etc.
- The backend which runs code on the server(s).
In this section, we are concerned with the static files. The usual way to present such files as a website on AWS is to store them inside an S3 bucket and use a CloudFront distribution to serve them.
Here’s an overview of how to achieve this:
- Create an S3 bucket.
- Upload the static files to the S3 bucket.
- Create a CloudFront distribution with an origin pointing at the S3 bucket.
- Create a domain name using Amazon Route 53 for your website.
- Create an SSL certificate using AWS Certificate Manager for the above domain name.
- Associate the SSL certificate to the CloudFront distribution to allow HTTPS access.
- If you don’t want the S3 bucket to have public access (which is recommended), you will need to create an origin access identity (OAI) for that origin in the CloudFront distribution, then edit the S3 bucket policy to allow read access to that OAI.
Benefits
There are several benefits of using Amazon S3 and CloudFront to serve static files, as opposed to the more traditional approach of a load balancer and web servers. First, it requires less time to serve requests from international users, thanks to the CloudFront CDN (both in terms of caching and geographical proximity to users). Also, there is no need to install, configure, manage, or patch web-server software or operating systems. This essentially means that you are no longer responsible for the performance and security of the infrastructure, as it is delegated to AWS.
In addition, you’ll benefit from AWS’s many years of experience, and will be able to focus your resources on the application itself, instead of on maintaining servers. Note that this is also a benefit of making the app and database tiers serverless (I’m mentioning it only once here).
The increase in costs related to CloudFront is largely offset by the lack of servers and the smaller number of IT teams needed to look after them. (You’ll still need system administrators and DevOps engineers for system-level configuration and maintenance.) In terms of storage costs, Amazon S3 is, on average, much cheaper than Amazon EBS, which is used to store server data.
Drawbacks
The main drawback of using Amazon S3 and Cloudfront is that the approach only works for applications that follow a modern design, with most of the code running in the client and occasionally making API calls to the backend. Older designs, where everything is served through, say, PHP files executed on the backend, won’t fit this pattern.
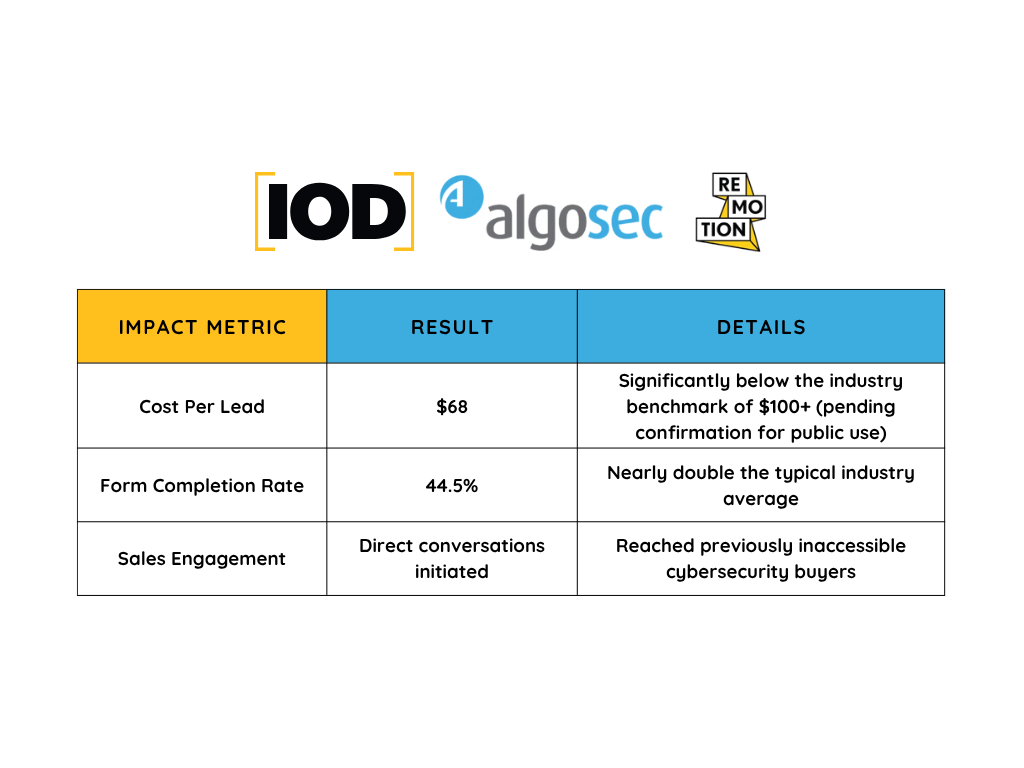
Are you interested in joining IOD’s growing global network of freelance tech experts and writers? Contact us and start to see for yourself how freelancing may be the preferred lifestyle choice for you this year.
Making the App Tier Serverless
Restructuring
We are now moving to the backend part of the application. The best way to make this tier serverless is to use Amazon API Gateway to handle the HTTP protocol, backed by AWS Lambda functions to actually execute the code. Serverless by nature, API Gateway allows you to easily create RESTful APIs. Lambda is AWS’s FaaS offering, which, as we mentioned earlier, is what allows you to run code without worrying about how and where it is run (the essence of serverless).
Moving to Lambda from either a monolithic application or from microservices will require a lot of work, as you’ll need to refactor a significant portion of your code. Using AWS Fargate, however, requires less work, since it enables you to run your application (or microservices) as Docker containers. Fargate thus offers a middle ground between “serverfull” and “serverless.” Like Lambda, it allows you to run your code without thinking about the underlying infrastructure. But, contrary to Lambda, your code will remain very similar in structure to that of a traditional setup—and your containers will incur costs, whether they are doing work or not. Interestingly, AWS just announced that Fargate is now available for Kubernetes.
Benefits
The main benefit of using Lambda is cost, since you pay only for code execution. As just mentioned, this is in contrast to servers, or even Fargate containers, which keep running and incurring costs, even when there is no activity. This can be mitigated by using scaling rules, but, even then, you’ll want to have at least two servers/containers running in order to ensure availability. In addition, Lambda has a very generous free tier, which allows you to run 1M of free requests per month and 400,000 GB-seconds of compute time per month.
Of course, using API Gateway means you’ll have a standardized, highly available, and highly performant RESTful API frontend. And using a solution based on API Gateway and Lambda together will automatically be highly available and instantly scalable (although this would depend, to a certain extent, on deeper tiers, such as the database).
Drawbacks
The obvious drawback and biggest hurdle for many businesses is refactoring the backend code to fit the new paradigm required by Lambda: stateless code. Stateless code is run on demand and must obviously stand on its own. This means that dependencies can’t be satisfied by simply calling other parts of the code, requiring more thought in terms of software architecture.
Another, more subtle problem of architectures based on Lambda functions is that debugging is harder. Since the code becomes very fragmented, locating the source of an error or bottleneck requires some form of “distributed debugging.” Thankfully, AWS X-Ray can help, although developers will need to do additional work, as it requires instrumentation of the code.
Finally, a typical problem associated with Lambda functions is a slight increase in execution time, compared to code running on a server. A Lambda function is typically “cold” when first created, and the first call to it will typically incur a “warming up” penalty, which can last for a few seconds. Subsequent calls will be much faster, with execution times quite close to those of code running on a server. However, problems can arise when Lambda functions call each other or when the workload is distributed through other means. The latencies incurred at each hop of the logical workflow can quickly add up and render the application very slow.
Making the Database Tier Serverless
Restructuring
Web applications usually require a database engine, such as MySQL or PostgreSQL. Typically, on AWS, such databases are run using Amazon RDS. You can switch from Amazon RDS to Amazon Aurora Serverless, which is currently compatible with both MySQL and PostgreSQL. Making the switch is quite painless: Simply create the Aurora database, migrate the existing database to Amazon Aurora, and change the connection strings used by the app tier to point to the new Aurora database.
Note: If you use NoSQL, check out Amazon DocumentDB (which is MongoDB compatible) and Apache Cassandra.
Benefits
Amazon Aurora Serverless offers automated scaling, built-in high availability, and high performance. Since it is serverless, you pay only for what you use, so with use cases like variable or unpredictable workloads, it can reduce costs.
Drawbacks
Amazon Aurora Serverless is only compatible with MySQL and PostgreSQL. You can move from your database engine to both, but this requires significant effort.
More importantly, with regards to the database tier, going fully serverless isn’t necessarily a better choice than a traditional model. Although Amazon RDS is not serverless, it does free you from the usual overhead of provisioning, installing, configuring, and patching the database server. It can even automatically increase the size of the underlying disk when the database becomes too large for the current disk size.
Additionally, Amazon Aurora Serverless is quite expensive compared to a similar RDS solution, so if your workload is consistently high, your costs are likely to increase significantly.
Conclusion
In this article, I walked you through a fairly typical example of how to make a traditional web application serverless. Whether or not this is a good idea for you depends on your particular situation. As demonstrated, going serverless doesn’t have to be all-or-nothing. In fact, it’s probably smart to modernize your application by taking incremental steps, going serverless where you’ll benefit the most.
The main advantage of serverless is the ability to delegate menial (but critical) tasks, such as system administration and server security, to AWS (an expert in this domain). You can also benefit from AWS in terms of security, reliability, and availability.
Going serverless also has some drawbacks, especially when it comes to refactoring your existing code, increased complexity, and potential performance penalties. Nevertheless, you will most likely benefit from moving some part of your workload to a serverless architecture. For example, repetitive background tasks can easily be moved from servers to a Lambda function. I recommend reviewing your current architecture and practices to determine which parts of your workload can benefit from such a move.