
Cloud environments provide a lot of benefits for advanced ML development and training including on-demand access to CPUs/GPUs, storage, memory, networking, and security. They also enable distributed training and scalable serving of ML models. However, training ML models in a cloud environment requires a highly customized system that links these different components and services together and allows for managing and consistently orchestrating ML pipelines. Managing a full ML workflow, from data preparation to deployment, is often really hard in a distributed and volatile environment like a cloud compute cluster.
Another important challenge is the efficient and scalable deployment of ML models. In a distributed compute environment, this requires configuring model servers and creating REST APIs, load balancing remote cluster requests, enabling authentication and security, etc. Also, ML model serving needs to be scalable, highly available, and fault-tolerant.
Kubernetes is one of the best solutions for managing distributed cloud clusters that addresses the above challenges. IBM’s Fabric for Deep Learning (FfDL) is a DL (Deep Learning) framework that marries advanced ML development and training with Kubernetes. It makes it easy to train and serve ML models based on different ML frameworks (e.g., TensorFlow, Caffe, PyTorch) on Kubernetes.
In this article, I’ll discuss the architecture and key features of FfDL and show some practical examples of using the framework for training and deploying ML models on Kubernetes. I’ll also address the key limitations of FfDL compared to other ML frameworks for Kubernetes and point out some ways in which it could possibly improve.
Description of FfDL Features
FfDL is an open-source DL platform for Kubernetes originally developed by the IBM Research and IBM Watson development teams. The main purpose behind the project was to bridge the gap between ML research and production-grade deployment of ML models in the distributed infrastructure of the cloud. FfDL is the core of many IBM ML products, including Watson Studio’s Deep Learning as a Service (DLaaS), which provides tools for the development of production-grade ML workflows in public cloud environments.
It’s no surprise that the team behind FfDL chose Kubernetes to automate ML workflows. Kubernetes offers many benefits for the production deployment of ML models including automated lifecycle management (node scheduling, restarts on failure, health checks), a multi-server networking model, DNS and service discovery, security, advanced application update/upgrade patterns, autoscaling, and many more.
More importantly, by design, Kubernetes is a highly extensible and pluggable platform where users can define their own custom controllers and custom resources integrated with K8s components and orchestration logic. This extensibility is leveraged by FfDL to allow ML workflows to run efficiently on Kubernetes, making use of available K8s orchestration services, APIs, and abstractions while adding the ML-specific logic needed by ML developers.
This deep integration between FfDL and Kubernetes makes it possible to solve many of the challenges that ML developers face on a daily basis. For the issues listed in the opening section, FfDL offers the following features:
- Cloud-agnostic deployment of ML models, enabling them to run in any environment where containers and Kubernetes run
- Support for training models developed for several popular DL frameworks, including TensorFlow, PyTorch, Caffe, and Horovod
- Built-in support for training ML models with GPUs
- Fine-grained configuration of ML training jobs using Kubernetes native abstractions and FfDL custom resources
- ML-model lifecycle management using K8s native controllers, schedulers, and FfDL control loops
- Scalability, fault tolerance, and high availability for ML deployments
- Built-in log collection, monitoring, and model evaluation layers for ML training jobs
Plus, FfDL is an efficient way to serve ML models since it uses the Seldon Core serving framework to convert trained models (Tensorflow, Pytorch, H2O, etc.) into gRPC/REST microservices served on Kubernetes.
FfDL Architecture
FfDL is deployed as a set of interconnected microservices (pods) responsible for a specific part of the ML workflow. FfDL relies on Kubernetes to restart these components when they fail and to control their lifecycle. After installing FfDL on your Kubernetes cluster, you can see similar pods:
kubectl config set-context $(kubectl config current-context) –namespace=$NAMESPACE
kubectl get pods
# NAME READY STATUS RESTARTS AGE
# alertmanager-7cf6b988b9-h9q6q 1/1 Running 0 5h
# etcd0 1/1 Running 0 5h
# ffdl-lcm-65bc97bcfd-qqkfc 1/1 Running 0 5h
# ffdl-restapi-8777444f6-7jfcf 1/1 Running 0 5h
# ffdl-trainer-768d7d6b9-4k8ql 1/1 Running 0 5h
# ffdl-trainingdata-866c8f48f5-ng27z 1/1 Running 0 5h
# ffdl-ui-5bf86cc7f5-zsqv5 1/1 Running 0 5h
# mongo-0 1/1 Running 0 5h
# prometheus-5f85fd7695-6dpt8 2/2 Running 0 5h
# pushgateway-7dd8f7c86d-gzr2g 2/2 Running 0 5h
# storage-0 1/1 Running 0 5h
Are you a tech blogger?
In general, FfDL architecture is based on the following main components:
- REST API
- Trainer
- Lifecycle Manager
- Training Job
- Training Data Service
- Web UI
Let’s briefly discuss what each of these does.
REST API
The REST API microservice processes user HTTP requests and passes them to the gRPC Trainer service. It’s an entry point that allows FfDL users to interact with training jobs, configure training parameters, deploy models, and use other features provided by FfDL and Kubernetes. The REST API supports authentication and leverages K8s service registries to load balance client requests, which ensures scalability when serving an ML model.
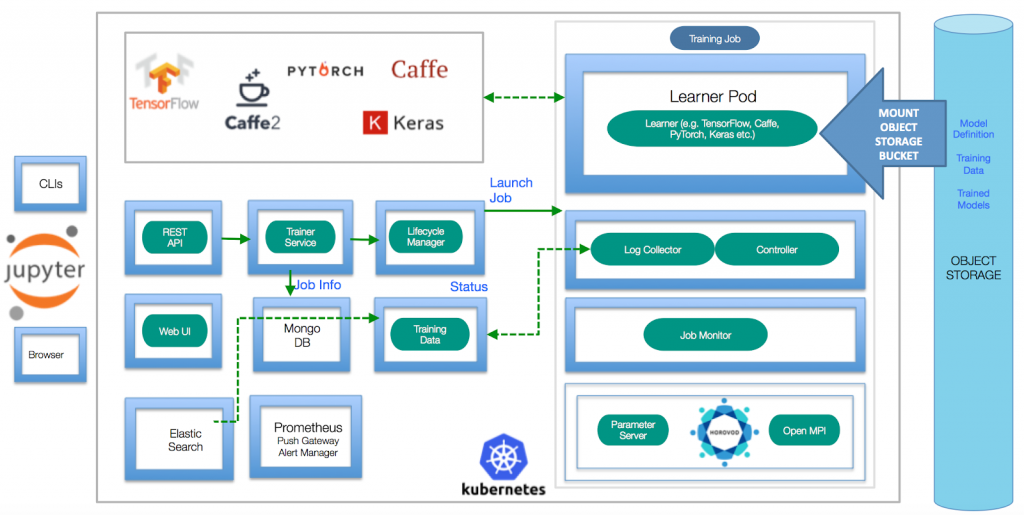
Figure 1: FfDL architecture (Source: GitHub)
Trainer
The Trainer microservice processes training job requests received via the REST API and saves the training job configuration to the MongoDB database (see Figure 1 above). This microservice can initiate job deployment, serving, halting, or termination by passing respective commands to the Lifecycle Manager.
Lifecycle Manager
The FfDL Lifecycle Manager is responsible for launching and managing (pausing, starting, terminating) the training jobs initiated by the Trainer by interacting with the K8s scheduler and cluster manager. The procedure according to which the Lifecycle Manager operates includes the following steps:
- Retrieve a training job configuration defined in the YML manifests.
- Determine the learner pods, parameter servers, sidecar containers, and other components of the job.
- Call the Kubernetes REST API to deploy the job.
Training Job
A training job is the FfDL abstraction that encompasses a group of learner pods and a number of sidecar containers for control logic and logging. FfDL allows for the launching of multiple learner pods for distributed training. A training job can also include parameter servers for asynchronous training with data parallelism. FfDL provides these distributed training features via Open MPI (Message Passing Interface) designed to enable network-agnostic interaction and communication between cluster nodes. The MPI protocol is widely used for enabling all-reduce style distributed ML training (see MPI Operator by Kubeflow).
Training Data Service
Each training job has a sidecar logging container (log collector) that collects training data, such as evaluation metrics, visuals, and other artifacts, and sends it to the FfDL Training Data Service (TDS). The FfDL log collectors understand the unique log syntax of each ML framework supported by FfDL. In turn, TDS dynamically emits this information to the users as the job is running. It also permanently stores log data in Elasticsearch for debugging and auditing purposes.
Web UI
FfDL ships with a minimalistic Web UI that allows for the uploading of data and a model code for training. Overall, the FfDL UI has limited features compared to alternatives such as FloydHub or Kubeflow Central Dashboard.
Training ML Models with FfDL
Now that you understand the FfDL architecture, let’s discuss how you can train and deploy ML jobs using this framework. The process is quite straightforward:
- Create a model code written in any supported framework (e.g., TensorFlow, PyTorch, Caffe).
- Containerize the model.
- Expose training data to the job using some object store (e.g., AWS S3).
- Create a manifest with a training job configuration using a FfDL K8s custom resource.
- Train your ML model via the FfDL CLI or FfDL UI.
- Serve the ML model using Seldon Core.
Assuming that you already have a working ML model code and training datasets, you can jump right to the FfDL model manifest parameters. The FfDL custom resource lets users define resource requirements for a given job, including requests and limits for GPUs, CPUs, and memory; the number of learner pods to execute the training; paths to training data; etc.
Below is an example of a FfDL training job manifest from the official documentation. It defines a TensorFlow job for training a simple convolutional neural network:
name: tf_convolutional_network_tutorial
description: Convolutional network model using tensorflow
version: "1.0"
gpus: 0
cpus: 0.5
memory: 1Gb
learners: 1
# Object stores that allow the system to retrieve training data.
data_stores:
- id: sl-internal-os
type: mount_cos
training_data:
container: tf_training_data
training_results:
container: tf_trained_model
connection:
auth_url: http://s3.default.svc.cluster.local
user_name: test
password: test
framework:
name: tensorflow
version: "1.5.0-py3"
command: >
python3 convolutional_network.py --trainImagesFile ${DATA_DIR}/train-images-idx3-ubyte.gz
--trainLabelsFile ${DATA_DIR}/train-labels-idx1-ubyte.gz --testImagesFile ${DATA_DIR}/t10k-images-idx3-ubyte.gz
--testLabelsFile ${DATA_DIR}/t10k-labels-idx1-ubyte.gz --learningRate 0.001
--trainingIters 2000
evaluation_metrics:
type: tensorboard
in: "$JOB_STATE_DIR/logs/tb"
# (Eventual) Available event types: 'images', 'distributions', 'histograms', 'images'
# 'audio', 'scalars', 'tensors', 'graph', 'meta_graph', 'run_metadata'
# event_types: [scalars]
According to the manifest, the TF training job will run using half of the node’s CPU capacity and will be processed by one learner. FfDL supports distributed training, meaning there can be multiple learners for the same training job.
In the data_stores part of the spec, you can specify how FfDL should access the training data and store the training results. Training data can be provided to FfDL using any block storage such as AWS S3 or Google Cloud Storage. After the training, the trained model with corresponding model weights will be stored under the folder specified in the training_results setting.
The framework section of the manifest defines framework-specific parameters used when starting learner’s containers. There, you can specify the framework version, initialization values for hyperparameters (e.g., learning rate), number of iterations, select evaluation metrics (e.g., accuracy), and location of the test and labeled data. You can define pretty much anything your training script exposes.
Finally, in the evaluation_metrics section, you can define the location of generated logs and artifacts and the way to access them. The FfDL supports TensorBoard, so you can analyze your model’s logs and metrics there.
After the manifest is written, you can train the model using either the FfDL CLI or FfDL UI. For detailed instructions on how to do this, please see the official docs.
Deploying FfDL Models
As I’ve already mentioned, FfDL uses Seldon Core for deploying ML models as REST/gRPC microservices. Seldon is a very powerful serving platform for Kubernetes and using it with FfDL gives you a lot of useful features out of the box:
- Multi-framework support (TensorFlow, Keras, PyTorch)
- Containerization of ML models using pre-packaged inference servers
- API endpoints that can be tested with Swagger UI, cURL, or gRPCurl
- Metadata to ensure that each model can be traced back to its training platform, data, and metrics
- Metrics and integration with Prometheus and Grafana
- Auditability and logging integration with Elasticsearch
- Microservice distributed tracing through Jaeger.
Any FfDL model whose runtime inference can be packaged as a Docker container can be managed by Seldon.
The process of deploying your ML model with FfDL is relatively straightforward. First, you need to deploy Seldon Core to your Kubernetes cluster since it’s not part of the default FfDL installation. Next, you need to build the Seldon model image from your trained model. To do this, you can use the S2I (Openshift’s source-to-image tool) and push it to Docker Hub.
After this, you need to define the Seldon REST API deployment using a deployment template similar to the one below. Here, I’m using the example from the FfDL Fashion MNIST repo on GitHub:
{
"apiVersion": "machinelearning.seldon.io/v1alpha2",
"kind": "SeldonDeployment",
"metadata": {
"labels": {
"app": "seldon"
},
"name": "ffdl-fashion-mnist"
},
"spec": {
"annotations": {
"project_name": "FfDL fashion-mnist",
"deployment_version": "v1"
},
"name": "fashion-mnist",
"oauth_key": "oauth-key",
"oauth_secret": "oauth-secret",
"predictors": [
{
"componentSpecs": [{
"spec": {
"containers": [
{
"image": "",
"imagePullPolicy": "IfNotPresent",
"name": "classifier",
"resources": {
"requests": {
"memory": "1Mi"
}
},
"env": [
{
"name": "TRAINING_ID",
"value": ""
},
{
"name": "BUCKET_NAME",
"value": ""
},
{
"valueFrom": {
"secretKeyRef": {
"localObjectReference": {
"name" : "bucket-credentials"
},
"key": "endpoint"
}
},
"name": "BUCKET_ENDPOINT_URL"
},
{
"valueFrom": {
"secretKeyRef": {
"localObjectReference": {
"name" : "bucket-credentials"
},
"key": "key"
}
},
"name": "BUCKET_KEY"
},
{
"valueFrom": {
"secretKeyRef": {
"localObjectReference": {
"name" : "bucket-credentials"
},
"key": "secret"
}
},
"name": "BUCKET_SECRET"
}
]
}
],
"terminationGracePeriodSeconds": 20
}
}],
"graph": {
"children": [],
"name": "classifier",
"endpoint": {
"type": "REST"
},
"type": "MODEL"
},
"name": "single-model",
"replicas": 1,
"annotations": {
"predictor_version": "v1"
}
}
]
}
}
The most important parts of this manifest are:
- BUCKET_NAME: The name of the bucket containing your model
- image: Your Seldon model on Docker Hub
There are also Seldon-specific configurations of the inference graph and predictors you can check out in the Seldon Core docs.
Conclusion: FfDL Limitations
As I showed, the FfDL platform provides basic functionality for running ML models on Kubernetes, including training and serving models. However, compared to other available alternatives for Kubernetes such as Kubeflow, the FfDL functionality is somewhat limited. In particular, it lacks flexibility in configuring training jobs for specific ML frameworks. Kubeflow’s TensorFlow Operator, for example, allows you to define distributed training jobs based on all-reduce and asynchronous patterns using TF distribution strategies. The Kubeflow CRD for TensorFlow exposes many more parameters than FfDL, and the FfDL specification for its training custom resource is not as well-documented.
Similarly, FfDL does not support many important ML workflow features for AutoML, including hyperparameter optimization, and has limited functionality for creating reproducible ML experiments and pipelines, like Kubeflow Pipelines does.
Also, the process of deploying and managing training jobs on Kubernetes is somewhat dependent on FfDL custom scripts and tools and does not provide a lot of Kubernetes-native resources, which limits the pluggability of the framework. The FfDL documentation for many important aspects of these tools is also limited. For example, there is no detailed description of how to deploy FfDL on various cloud providers.
Finally, the FfDL UI does not provide as many useful features as FloydHub and Kubeflow Central Dashboard. It just lets users upload their model code to Kubernetes.
In sum, to be a tool for the comprehensive management of modern ML workflows, FfDL needs more features and better documentation. At this moment, it can be used as a simple way to train and deploy ML models on Kubernetes but not as a comprehensive platform for managing production-grade ML pipelines.
