By Maish Saidel-Keesing
 I have been working on a project for a while that includes the deployment of a large number of moving parts that are in a significant state of flux. Drops every two weeks, new features added all the time, and, of course, with a system this size there is a great amount of complexity involved. Complexity in the Continuous Integration stage, complexity with the end-to-end testing, and, definitely, complexity with the Continuous Deployment.
I have been working on a project for a while that includes the deployment of a large number of moving parts that are in a significant state of flux. Drops every two weeks, new features added all the time, and, of course, with a system this size there is a great amount of complexity involved. Complexity in the Continuous Integration stage, complexity with the end-to-end testing, and, definitely, complexity with the Continuous Deployment.
A good part of the intricacies comes from the fact the development team wants to assure that the deployment will be cloud-agnostic. But before I go into if this would be a good or a bad thing, let me first explain what this means, and offer a few examples.
It is no secret that almost no OpenStack cloud is identical to another. The network setup could be different (provider networks vs. private networks). Some clouds have Swift installed by default, while others do not. There are nuances and differences between an on-premises OpenStack deployment and using an OpenStack cloud provider, such as RackSpace. APIs are different, versions are different. This makes things very difficult for people writing software to interact with the cloud to address a fully cloud agnostic solution. APIs, authentication mechanisms, and the way you can access resources will change from one cloud to another.
The way you request a public network address (if you even can) will change from cloud to cloud. And when this is the case, go figure how you can make a repeatable deployment that will work, wherever your customers want it. It isn’t easy.
Becoming Cloud-Agnostic
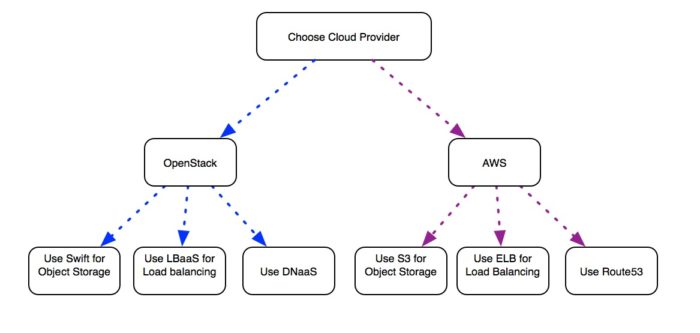
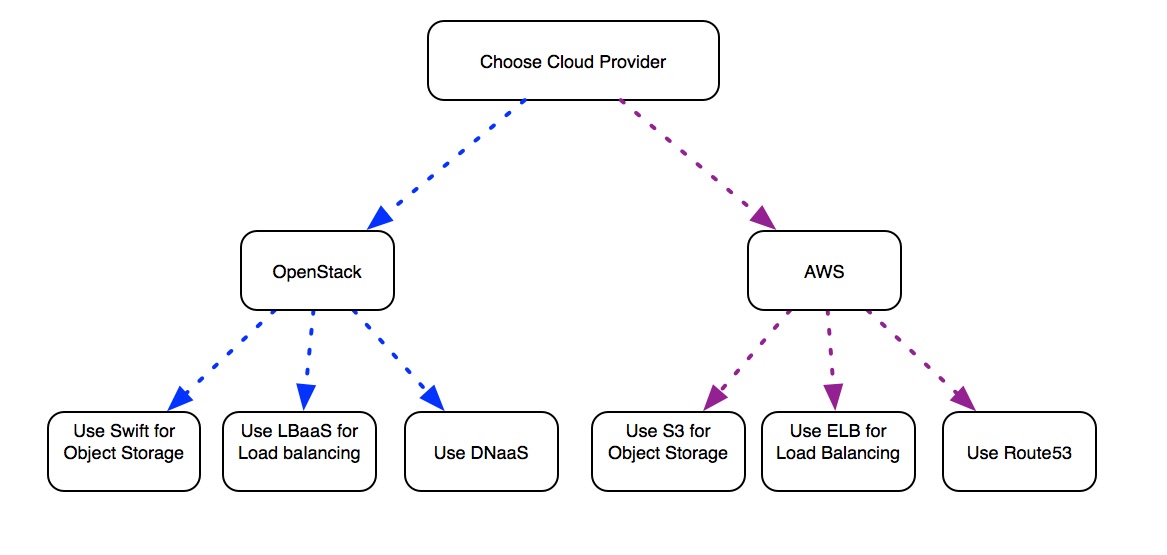
In order to address this, people come up with the idea of making sure that no matter where we deploy, the deployment will be the same.
For example: You need an object storage service to store files. You cannot rely on the fact that Swift will be available in every cloud. If that is the case, you deploy your own Swift in the cloud to serve your applications.
Another example is logging and monitoring. Not every cloud has a built-in mechanism for shipping logs (most OpenStack clouds do not), nor a way to aggregate these logs into one system that allow you collect the data over time (Elastic Search, for example). And if this is not the case, you then deploy your own as part of product you are supplying.
Sounds great, doesn’t it? A repeatable deployment that will work no matter where you deploy it, on-premises, in OpenStack, in AWS, or perhaps even in Azure?
But becoming “cloud-agnostic” has a significant price attached to it.
The Hidden Cost
The biggest cost here is the one of support and maintenance of infrastructure that you should be consuming, instead of dealing only with your code.
Let me explain: You provide an application that tracks the fitness habits of the user, and your application is—of course—the best in the world! It tracks when a person is running, walking, sleeping, and even how many calories they burn riding in the elevator from the 1st to the 40th floor. Your app is that accurate.
But, you want to be free of the dependency of a cloud provider. You simply cannot rely on the cloud provider services being available. In the case of AWS, we’re talking about:
- S3 Object Storage
- Elastic Search
- DynamoDB
- RDS
- ELB
Why? Because you cannot assume that these services will be available in each and every cloud platform. In order for your applications to work in every cloud, you have to deploy on your own:
- Object Storage
- ELK
- NoSQL database (Mongo/Couchbase)
- SQL database (MySQL/Postgres)
- HAproxy
Not only do you have to deploy them, you have to deploy them in a fashion in which they are redundant, scalable, and meet your performance requirements. In doing so, you become not only a company that writes software to track users’ health and fitness, but one that maintains a huge amount of infrastructure underneath in order to provide a service to track user health and fitness.
I am a big supporter of consuming services provided to you by your cloud provider: they are services you can count on. They are tried and tested. (You are billed for almost every bit and byte you use, so they damn well better be!) The services are managed 24/7 by someone else that you can rely on (after all, you rely on them to deploy the rest of your business, don’t you?)
I would highly recommend that you make use of as much of -aaS products from your cloud provider as possible. It will free you up to deal with what you are actually supposed to be doing —providing the best product to your customers—and not have to deal with managing and supporting infrastructure, which someone else already does 24/7 at a much larger scale.
What this does require though is that you make your orchestration software a lot more intelligent to be cloud-aware (and not cloud-agnostic!) Start off on one platform and deploy it in the best way possible. When you decide to expand to the next platform, do the same, and make sure you are using the built-in service available to to you for that specific platform.
Final Thoughts
It does make things more complicated—at least at the orchestration layer—but it will definitely pay off in the long run. Free yourself from managing ‘infrastructure layers’ that the cloud provider gives, mostly built in. Will it be cheaper on the monthly bill? Maybe not. But it will be cheaper in the long run. Your developers will be able to focus on writing the best fitness software in the world, and maybe even come up with a way to track how many calories you have burnt while eating your lunch!
= = =
Maish Saidel-Keesing is a cloud architect and virtualization veteran who has been involved in IT for the past 17 years. He is a world-renowned author of two books on enterprise architecture: VMware vSphere Design Guide and OpenStack Architecture Design Guide. He has a popular blog Technodrone and most of the time he can be found lurking on Twitter (@maishsk).
