
For the past few hours, I’ve been working on training a neural network to translate cat speech into English. I’ve carefully optimized my parameters and tested different network depths, batch sizes, number of epochs, and optimization algorithms. I’m pretty happy with the 92% accuracy rating that I’m getting now, and, with a few more tweaks, I’m confident that I can get to 95% accuracy.
Okay… none of that is true.
In reality, I’ve spent the past few hours playing while True: learn(), a computer game where you take on the persona of a software developer who decides to delve into machine learning in order to better understand his cat.

After a quick search on “CatOverflow,” the video game’s main character starts building and training models. The game is quite well done, allowing users to build, train, and deploy models with a simple drag-and-drop interface. Once you have a trained working model, you can easily deploy it in different environments and even include it as a layer in a different model (transfer learning). The game even includes “CatHub,” a code repository management system that allows you to choose different versions of schemas to reuse in various experiments.
If only real life were that simple!
The Reality
As pointed out by Luke Marsden, Founder and CEO of Dotscience, the tooling and workflows that enable “controlled collaboration” and “continuous integration” in software projects have not reached a parallel level of maturity when it comes to ML projects.
Let’s take a look at this issue via a real-world example. A standard development cycle looks something like this:
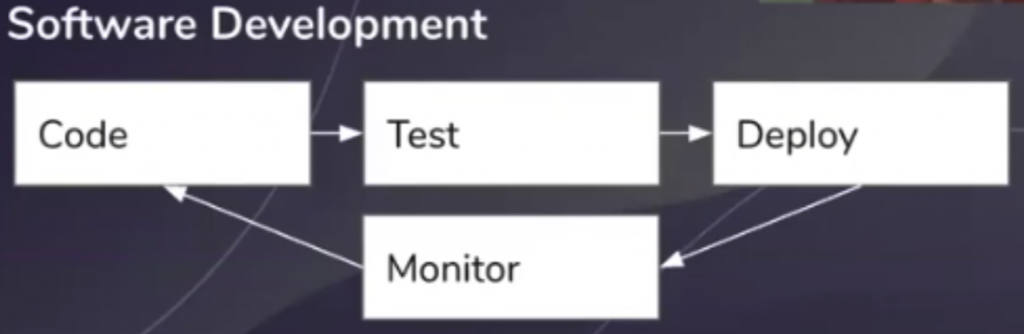
- Write the code.
- Test the code.
- Deploy the code.
- Monitor.
- When you encounter an issue, update the code and redeploy it.
It’s a relatively straightforward process, and it can be made even easier by using some kind of versioning software, usually Git. A common convention is that the latest commit on the “master” branch of your repo is the version deployed in production. When a bug is encountered, a developer can simply branch off of the master branch, fix the bug, merge back into the master branch, and deploy.
Now, let’s consider how this development cycle looks for machine learning:
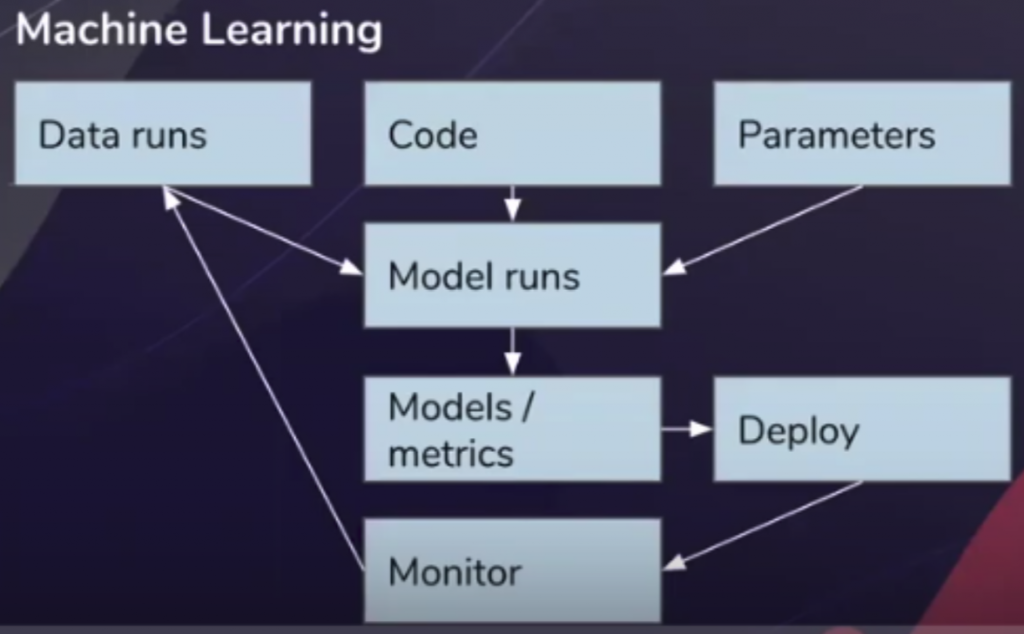
- Write code that defines how your model should “learn” from examples. Based on the topic you’re studying, you’ll probably end up with a few algorithms you’ll want to test out.
- Define your source data set.
- Write code to prepare the data set that you’ll “train” your model on. This can involve data cleaning, image augmentation, and other steps. It will also involve splitting the data set into “training data,” “test data,” and, in all likelihood, “validation data.”
- Train your model. After training, your model is a stand-alone deployable artifact. It is no longer connected to how it was trained or to the data that it was trained on, making it easy to lose track of those things.
- Test. Pay special attention to the runtime/accuracy ratio. Tweaking parameters and data sets can alter this ratio in either direction.
- Deploy.
- Monitor.
- When you encounter an issue you cannot simply update the code and redeploy it. You first have to ask: Which model version was deployed? How was this model trained and on which data set? What were the parameters?
TLDR, right?
Machine learning has WAY more moving parts than “vanilla” software development. It’s a few orders of magnitude more difficult to reproduce identical models, not to mention identify which version of the original code was trained on which data set and made which specific decision. Two models created by running an identical Python script will end up producing completely different artifacts when trained on different data sets.
All of this also makes it more difficult for developers to collaborate on ML projects, since all those additional moving parts need to be in sync for them to work together productively.
Why Is This Such a Problem?
Besides the obvious problems caused by the immaturity of the current MLOps scene, there are additional issues unique to ML that you are likely to face. Some of them are:
- Regulations: Many countries—including the US, Canada, the EU, and Israel—have regulations regarding reproducibility, traceability, and verifiability. These regulations especially apply to the financial services industry, but government regulations guiding the use of AI can be found in industries ranging from healthcare and biotech to government security.
- Data drift: Over time, you can expect the type of input your trained model receives to change. When this happens, you’ll want to adjust your model to perform better. But if you don’t understand exactly how your model got to this state, you can’t hope to know what adjustments to make to it or what additional data to train it on.
- Starting over: If you don’t have access to the exact code version that generated and compiled the model, you’ll need to start over from scratch when the model needs even just a slight improvement.
- Time and resource investment: Considering the costs and man-hours involved in producing even a simple model, it’s obvious that the costs of not being able to reproduce, verify, and trace a model are immense.
To Make Matters Worse…
People seem to forget that, in the words of Jordan Edwards, Principal Program Manager for MLOps on Azure ML at Microsoft, “Data scientists are not software engineers. And they’re not even engineers.” They are scientists, and production infrastructure and package version management are simply not things “they’re interested in at all.”
Data scientists today do have a number of techniques at their disposal to manage their development cycles, including:
- Jupyter notebooks in Google Drive or OneNote
- Emailing/Slacking Python files, Jupyter Notebooks, and model artifacts to each other
- Post-its (seriously)
Of course, these habits are terrible. They open up companies in specific sectors (financial, medical, etc.) to legal trouble while costing them millions of dollars in development expenses—never mind the stress and morale problems a company will have when facing the headache of managing such a disorganized system.
Imagine if we could provide ML developers and data scientists a system more like this:

This, they might actually use!
Possible Solutions
Before you throw in the towel and give up on implementing an effective AI workflow, you should know about some startups that have made significant headway in helping engineers manage their model-training challenges. Companies like Allegro AI and Iguazio are stepping up to the plate with robust and innovative solutions.
In summary, businesses have a lot to gain by looking into how Machine Learning can be put to use in their industry. However, their first order of business should be to come up with a plan as to how they are going to properly manage and scale their ML pipelines first. You can find plenty of resources for some further reading on this topic online, including here and here.
