
Serverless is a trendy word nowadays. You hear it at conferences, workshops, and all around the Internet. However, many in our industry might still be struggling with truly understanding the concepts behind it or when it’s best to use Serverless. This post offers a simple walk-through around the current Serverless ecosystem.
What is Serverless?
The way I see it, there are two top definitions for Serverless computing; one wider-known, which defines it as the tendency of eliminating the server’s hardware/software management. The other way Serverless is referenced, which is more specific, is known as FaaS (Function as a Service). This post covers the latter.
Full Stack Python defines FaaS this way: “A deployment architecture where servers are not explicitly provisioned by the deployer. Code is instead executed based on developer-defined events that are triggered….”
Let’s go a little deeper and break down this definition, so we can understand it better:
“Serverless is a deployment architecture…”
This suggests that Serverless is a new architectural approach for building software that changes the mindset about how software is organized, deployed, and executed on the server.
“… where servers are not explicitly provisioned by the deployer…”
One important aspect to keep in mind from this definition is that it never says that there aren’t servers. There are! It’s just that developers don’t need to worry about provisioning anymore. If you have worked with containers in the past, you may find this workflow somehow familiar. You’re provided with a mechanism that runs containers in your local environment and that should guarantees that your code will work on whatever hardware is going to be run, because at the end, the code will run into a similar container.
“… Code is instead executed based on developer-defined events that are triggered…”
Serverless still means code. What changes is how and when it is executed. Serverless is pretty much like developing event-driven apps. Serverless is an architectural-hardware-agnostic approach that consists of a set of independent functions that are executed when a certain event is triggered. In other words, you write a function, you deploy it into a cloud provider and you attach it to an event.
Serverless: Pros and Cons
As inferred before, with Serverless architecture, developers pay attention to individual functions. Rather than focusing on operating systems, hardware, and scaling aspects, they keep their attention on code and where to run it. Let’s talk about some advantages this approach offers:
- No need to manage servers. In other words, no virtual machines, no instances, no hardware. Only code and some configurations are important. Again, this may sound familiar to you if you have worked with containers or any PaaS. A key difference is that with FaaS you will need to follow the provider’s guidelines, and for using containers, you will need to know how the engine for containerizing works (i.e. Docker).
- Pay only for the compute you use. The cloud provider will only charge you for the time the function takes to run. The function is not running all the time. It’s “sleeping” until it gets called by an event.
- Horizontal scaling out of the box. You don’t need to specify how many instances will be required for handling current traffic, the cloud provider does this for you. Meaning, it will create as many function instances as needed for covering your current traffic.
However, Serverless architecture comes with some disadvantages, as well.
- Cold starts: As the function is regularly “sleeping,” the first call takes more time as it needs to “wake up” first. Meaning, the provider needs to move the code to a container and actually run it. Subsequent calls are faster. Cold start is the first obstacle to tackle once you have decided to go with this architecture.
- Vendor restrictions: You are limited by your provider when it comes to max time execution, RAM consumption, supported languages, and API integrations. Basically, the provider sets the rules and there is not that much you can do about it.
- Vendor lock-in: Once you deploy your functions into a cloud provider, it will be difficult to change the provider (due to API and services integrations). So choose wisely!
Are you seeking high-quality, expert-based tech content for your brand? Contact us. We create content for some of the top brands in tech.
Serverless Implementation
You can deploy your functions on premise or in the cloud. If you want to build an FaaS environment in your own hardware or data center, check one of the following options. (All based in containers.)
The above options are for building all the orchestration required for supporting an FaaS platform. If, let’s say, you want to provide FaaS internally in your company using on-premise infrastructure.
The major cloud players already offer FaaS in their portfolios, including:
Choosing one or another depends on your needs. They may seem to work the same way, but there are a lot of factors to be considered in choosing one: max time execution, max memory consumption, pricing, supported languages, and API integrations.
Writing an application with Serverless architecture requires a change in the development mindset. Apps should be built based on functions with these type of qualities:
- Speedy and singular: Functions should only do one thing, and they should do it as fast as possible.
- Share nothing: Since the function will be alive for a few seconds, you should not rely on it for sharing or saving statuses. The function will die after its execution, so it won’t save anything.
- No hardware affinity: You don’t really know where the provider will execute your function. So while you write it, consider that the first time it will run may be on a Debian machine with an intel CPU, and the next time, on a Red Hat machine with an ARM architecture.
- Design for failures: Providers usually offer mechanisms for being aware about whether or not the functions were executed correctly. Use them! Implement the retry mechanism, just as you would in other architectures.
Two other interesting aspects to consider are testing and continuous integration. How could you write functional tests if your application was a set of a well-defined functions? What changes would be required in CI pipelines for deploying FaaS pieces of software? If your function talks with a provider’s API, how would you unit test it? Those questions require their own article for answering. However, if you want to dig further, check out this guide or this one.
When to Use FaaS
Here are some hints:
- REST APIs: If what you need to implement is a set of endpoints connected to any data source also offered by the same provider, FaaS in an excellent option.
- IoT Stream events: If the requirement is to save data reads from sensors so you can process the data later on, FaaS would also work. Write an endpoint which connects the device with your database through a function.
- Backend mobile app: If you handle your authentication based on tokens, you can write the entire backend of an app using FaaS.
Reducing costs is really a good reason for choosing Serverless. Do the math to be certain that’s the case for you.
I have mentioned some apps that run on Serverless, but I haven’t told you which ones don’t:
- Web Sockets: Definitely won’t work. Remember, functions will be alive for a few seconds and won’t save any status.
- Serving statics: CDNs are for this, Serverless is not a CDN.
Writing Your First Function
In order to write an FaaS, we can use either the web interface offered by the cloud provider. (Check this link for doing so on GCP.) Or some kind of framework which allows us to deploy our functions into the cloud from our local machines. For keeping the simplicity of this overview, let’s write a small function (hello world) in Python using the Serverless Framework.
First, we need a Node environment and to install the framework itself, I will assume you have the environment already. For installing the framework, we should execute:
sudo npm install -g serverless
This framework allows us to connect with many providers. Here, the function will be deployed on Amazon. I’m skipping how to configure the credentials for Amazon, but you can check out how in this link. Once you configure them, you can create a Python function using a template:
serverless create –template aws-python3 –name hello-world
This creates a Python file (handler.py) with a hello function (very readable in my opinion) that looks like:
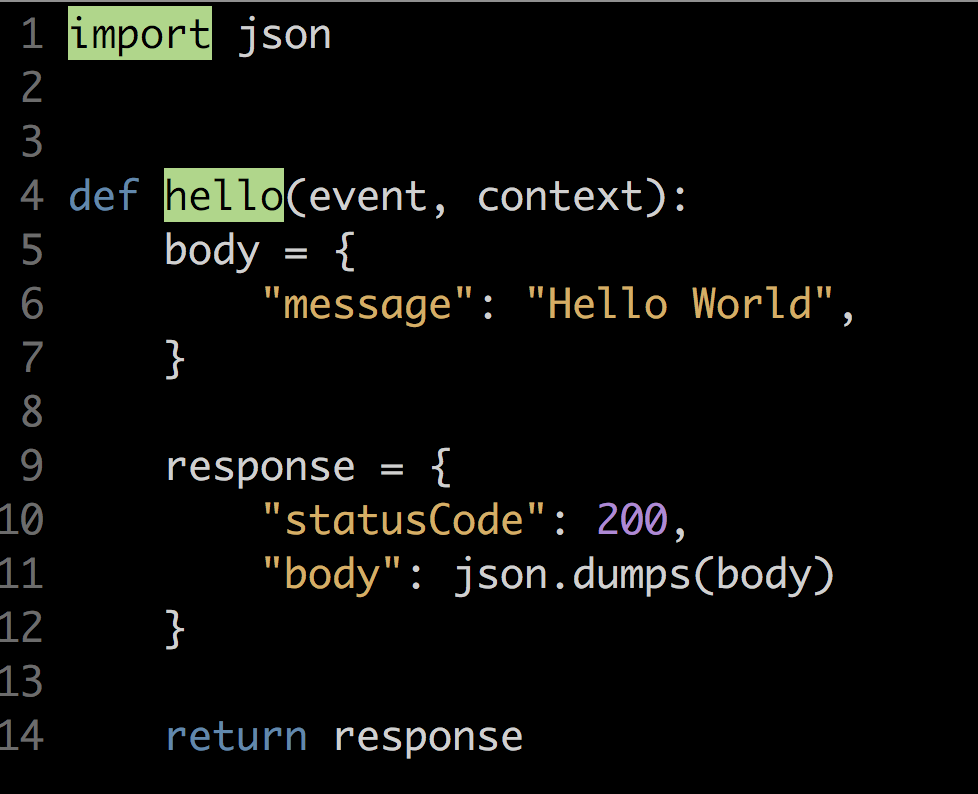
Source: Jorge Galvis
And a yml file (serverless.yml) file which is where you can tell to the framework how the function should be run.
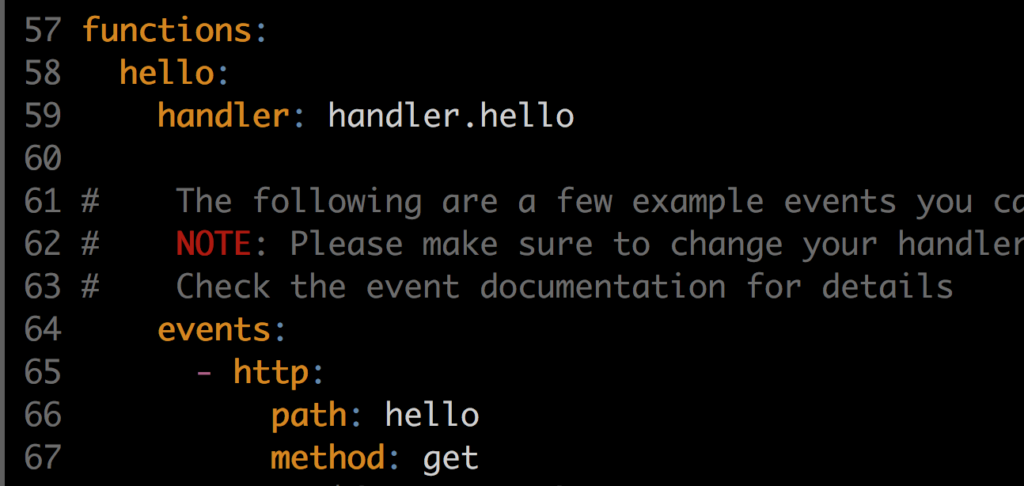
Source: Jorge Galvis
As you may have noticed, I’m telling the framework to run the function when a defined URL (given by the provider) ending in /hello is called under the method GET. With the boilerplate code we can actually deploy the function with:
Serverless deploy -v
While deploying, check the log out!, it will tell you exactly what the deployment process is doing. When done, you can hit the endpoint using curl:
$ curl https://xyz.amazonaws.com/hello
Keep in mind that in your environment the URL will be different.
You can find a great detailed example here. The author uses the Chalice microframework.
Conclusions
Serverless is an architectural approach for applications based on a set of unique functions that are simple, fast, stateless, and know nothing about the attached hardware. Not all apps fit into Serverless, though, so don’t allow trendy technologies to affect your current architecture. If your app is working just fine as it is–performance is good, maintenance is relative easy, etc.–and within the budget, you probably won’t need to change anything. FaaS may be most appropriate when it comes to REST APIs. Although I have seen it being used for background processing, as well.
Once you have deployed an app using FaaS, never forget to monitor the functions in terms of costs and performance. We don’t want surprises in the monthly bill, right? Finally, if Serverless is not helping you to save money, maybe you should reconsider its use.
